项目实践导读 本小节将和你分享一些小的实践项目,完成这些小项目,需要你具备非常扎实的python基础知识,此外,还需要你具备良好的计算机知识。 如果这两样你都不具备,那么学习本小节会非常困难,毕竟,编程不等于编程语言,编程是计算机,工程,编程语言的综合运用。
本小节已经完成的文章如下:
项目日志–logging详解
python虚拟环境在开发与生产环境下的使用
python命令行工具click
python创建定时任务
python库打包分发setup.py编写指南
项目日志–logging详解 1.日志级别 1.1 日志级别含义 不同的日志级别代表不同的紧急程度,反应出系统运行的状况,下表是不同日志级别及其适用场景
级别
适用场景
DEBUG
记录详细信息,用于程序调试
INFO
记录可证明程序正常执行的信息
WARNING
记录意外信息,此时程序仍可正常执行,但需要关注
ERROR
明显发生一些错误,部分功能无法正常工作,需要立刻处理
CRITICAL
严重错误,程序已经不能继续执行了
一个系统,要根据日志的内容将其归入到不同的级别中,相同级别的日志输出到同一个日志文件中,这样,可以快速发现问题,定位问题。
如果将所有级别的日志都输出到同一个日志文件中,那么观察日志就变得麻烦,ERROR日志混杂其他级别日志中,不利于问题的发现和追查。
1.2 配置日志级别 下面的程序,简单的演示如何配置日志的级别
import logginglogging.basicConfig(level=logging.ERROR) logging.debug('debug message' ) logging.info('info message' ) logging.warning('warning message' ) logging.error('error message' ) logging.critical('critical message' )
程序输出结果
ERROR:root:error message CRITICAL:root:critical message
通过设置level=loggin.ERROR,日志在输出的时候,只有大于等于ERROR的日志才会被输出,如果不设置level,默认是WARNING级别。
2. Logger Logger是记录器,是程序可以直接使用的接口,为了在实际工作中实现复杂的技术要求,我们不会使用1.2中的的日志方法,而是创建Logger,用Logger管理日志的输出
创建方法如下
logger = logging.getLogger('my_log' )
使用示例如下
import logginglogger = logging.getLogger('my_log' ) logger.setLevel(logging.ERROR) logger.debug('debug message' ) logger.info('info message' ) logger.warning('warn message' ) logger.error('error message' ) logger.critical('critical message' )
程序输出结果
error message critical message
3. Handler 前面的两个例子中,程序运行时,日志直接输出到终端,这是因为,如果不显式的创建一个Logger,就会默认创建一个root logger,如果不指定Handler,则默认使用StreamHandler将日志输出到标准输出上。
Handler决定了日志的信息最终输出到哪里,最常用的是FileHandler 和 StreamHandler
3.1 FileHandler FileHandler 将日志输出到指定的文件中
import logginglogger = logging.getLogger('my_log' ) file_handler = logging.FileHandler("test.log" ) file_handler.setLevel(logging.ERROR) logger.addHandler(file_handler) logger.setLevel(logging.DEBUG) logger.debug('debug message' ) logger.info('info message' ) logger.warning('warn message' ) logger.error('error message' ) logger.critical('critical message' )
执行程序,会创建一个test.log,文件里的内容是
error message critical message
这里你会看到两次执行setLevel,logger.setLevel设置的日志级别决定了什么类型的日志会进入到Handler中,而file_handler.setLevel设置的日志级别决定了什么样的日志会写入到文件中。
logger设置日志级别相当于一个总开关,而file_handler设置的日志级别则是一个小开关,毕竟,一个logger下可以添加多个handler,每个handler都可以设置各自的日志级别。
3.2 StreamHandler StreamHandler可以将日志输出到流中,例如sys.stdout, sys.stderr, 以及实现了write和flush方法的类文件对象。
import loggingimport syslogger = logging.getLogger('my_log' ) file_handler = logging.FileHandler("test.log" ) file_handler.setLevel(logging.ERROR) logger.addHandler(file_handler) stream_handler = logging.StreamHandler(sys.stdout) stream_handler.setLevel(logging.WARNING) logger.addHandler(stream_handler) logger.setLevel(logging.DEBUG) logger.debug('debug message' ) logger.info('info message' ) logger.warning('warn message' ) logger.error('error message' ) logger.critical('critical message' )
上面的代码,增加了一个stream_handler,将日志输出到标准输出,file_handler将日志输出到文件,这就是handler的用处。
logger提供了日志输出接口,一条日志可以通过handler同时输出到不同的文件或stream中。在使用docker镜像时,通常会将程序的日志输出到标准输出中,于此同时也会保留一份在文件中,遇到类似这样的场景,你就可以像上面这段代码一样将日志多个目的地同时输出。
4.1 日志格式 格式化器可以用来定义日志的内容和格式,有许多信息是不需要你在日志信息中自己搜集处理的,比如日志输出时所在的filename,调用日志输出的函数名,这些信息logging模块已经帮你搜集处理好,你只需要配置那些输出,以及以什么方式输出即可。
%(name)s Logger的名字 %(levelno)s 数字形式的日志级别 %(levelname)s 文本形式的日志级别 %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 %(filename)s 调用日志输出函数的模块的文件名 %(module)s 调用日志输出函数的模块名| %(funcName)s 调用日志输出函数的函数名| %(lineno)d 调用日志输出函数的语句所在的代码行 %(created)f 当前时间,用UNIX标准的表示时间的浮点数表示| %(relativeCreated)d 输出日志信息时的,自Logger创建以来的毫秒数| %(asctime)s 字符串形式的当前时间。默认格式是“2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d 线程ID。可能没有 %(threadName)s 线程名。可能没有 %(process)d 进程ID。可能没有 %(message)s 用户输出的消息
创建一个Formatter对象时,传入的fmt参数里可以从中选取你想要输出的内容。
下面的代码演示了如何设置日志的格式和内容
import loggingimport syslogger = logging.getLogger('my_log' ) file_handler = logging.FileHandler("test.log" ) file_handler.setLevel(logging.ERROR) formater = logging.Formatter(fmt='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s' , datefmt='%Y-%m-%d %H:%M:%S' ) file_handler.setFormatter(formater) logger.addHandler(file_handler) stream_handler = logging.StreamHandler(sys.stdout) stream_handler.setLevel(logging.WARNING) logger.addHandler(stream_handler) logger.setLevel(logging.DEBUG) logger.debug('debug message' ) logger.info('info message' ) logger.warning('warn message' ) logger.error('error message' ) logger.critical('critical message' )
fmt 参数设置了以什么样的顺序输出哪些内容,datefmt设置了时间的格式。
由于只在file_handler进行了设置,因此,这个格式也只在file_handler 起作用,stream_handler记录的日志不受影响。在test.log中输出的内容如下:
2019-01-23 20:55:19 demo1.py[line:21] ERROR error message 2019-01-23 20:55:19 demo1.py[line:22] CRITICAL critical message
4.2 json格式 工作中,往往希望将日志以json格式输出,这样便于收集处理,例如使用logstash收集日志。
想要输出json格式的日志,需要创建一个新的类,继承logging.Formatter并重载format方法。
format方法传入一个record对象,这里保存了日志的所有数据,只需要将数据进行整理最后使用json.dumps方法转成json格式数据返回即可。
不过在这之前,仍然需要定义fmt, 我在示例中将fmt定义为’timestamp,filename,lineno,levelname,msg’ , 我希望能按照如下顺序和内容输出json格式的日志。
下面的代码演示如何自定义一个json的Formatter并使用
import loggingimport jsonimport sysfrom collections import OrderedDictclass JsonFormatter (logging.Formatter): def __init__ (self, *args, **kwargs ): super ().__init__(*args, **kwargs) self .parse() def parse (self ): self .fields = self ._fmt.split("," ) def format (self, record ): """ 重载format方法,返回json格式字符串 :param record: :return: """ log_record = OrderedDict() for field in self .fields: if field == 'timestamp' : log_record[field] = self .formatTime(record, self .datefmt) else : log_record[field] = record.__dict__.get(field, "" ) log_record = json.dumps(log_record, ensure_ascii=False ) return log_record logger = logging.getLogger('my_log' ) file_handler = logging.FileHandler("test.log" ) file_handler.setLevel(logging.ERROR) formater = JsonFormatter(fmt='timestamp,filename,lineno,levelname,msg' , datefmt='%Y-%m-%d %H:%M:%S' ) file_handler.setFormatter(formater) logger.addHandler(file_handler) stream_handler = logging.StreamHandler(sys.stdout) stream_handler.setLevel(logging.WARNING) logger.addHandler(stream_handler) logger.setLevel(logging.DEBUG) logger.debug('debug message' ) logger.info('info message' ) logger.warning('warn message' ) logger.error('error message' ) logger.critical('critical message' ) logger.error("中文" )
test.log输出的内容为
{"timestamp": "2019-01-23 21:47:46", "filename": "demo1.py", "lineno": 42, "levelname": "ERROR", "msg": "error message"} {"timestamp": "2019-01-23 21:47:46", "filename": "demo1.py", "lineno": 43, "levelname": "CRITICAL", "msg": "critical message"} {"timestamp": "2019-01-23 21:47:46", "filename": "demo1.py", "lineno": 44, "levelname": "ERROR", "msg": "中文"}
5. Filter,过滤器 通过设置logger和 handler的日志级别来实现日志的过滤,但这样的控制还是过于粗糙,Filter可以实现更加细致的过滤。
logging.Filter有一个filter方法,定义如下
def filter (self, record ):
入参record对象包含了日志的全部信息,这些信息都在record.__dict__中,你可以通过继承logging.Filter类来实现更加复杂的过滤,比如,工作中需要将不同级别的日志输出到不同的日志文件中,这样查找的效率会更高。
下面是一个自定义Filter的示例
class LogLevelFilter (logging.Filter): def __init__ (self, name='' , level=logging.INFO ): super ().__init__(name) self .level = level def filter (self, record ): return record.levelno == self .level
重载了filter方法,只有当日志的级别和Filter的过滤级别相同时才会输出日志,下面的代码演示了如何使用这个过滤器
import loggingimport jsonimport sysfrom collections import OrderedDictclass JsonFormatter (logging.Formatter): def __init__ (self, *args, **kwargs ): super ().__init__(*args, **kwargs) self .parse() def parse (self ): self .fields = self ._fmt.split("," ) def format (self, record ): """ 重载format方法,返回json格式字符串 :param record: :return: """ log_record = OrderedDict() for field in self .fields: if field == 'timestamp' : log_record[field] = self .formatTime(record, self .datefmt) else : log_record[field] = record.__dict__.get(field, "" ) log_record = json.dumps(log_record, ensure_ascii=False ) return log_record class LogLevelFilter (logging.Filter): def __init__ (self, name='' , level=logging.INFO ): super ().__init__(name) self .level = level def filter (self, record ): return record.levelno == self .level logger = logging.getLogger('my_log' ) file_handler = logging.FileHandler("test.log" ) file_handler.setLevel(logging.INFO) formater = JsonFormatter(fmt='timestamp,filename,lineno,levelname,msg' , datefmt='%Y-%m-%d %H:%M:%S' ) file_handler.setFormatter(formater) file_handler.addFilter(LogLevelFilter(level=logging.INFO)) logger.addHandler(file_handler) logger.setLevel(logging.DEBUG) logger.debug('debug message' ) logger.info('info message' ) logger.warning('warn message' ) logger.error('error message' ) logger.critical('critical message' ) logger.error("中文" )
6.LoggerAdapter 扩展 4.1 小节中介绍的Formatter允许你定义日志的输出的格式和内容,但这些信息往往不能满足实际需求。
比如在一个web服务中,我们希望记录下一次请求的客户端ip地址,也可能是方便追查问题的trace_id,也可能是此次请求的uri, 这些信息都是logging模块无法主动收集的,而且,每次请求中,这些信息都是变化的,如果能将这些信息记录下来,那么对于信息的统计和分析是非常有帮助的。
LoggerAdapter 是对logger一个扩展,它允许你传入一个字典,字典里的数据可以在record 的__dict__中查询到,logging模块自己收集到的信息也放在__dict__。
每次请求到达时,你可以先将和这次请求相关的信息收集到,然后创建一个LoggerAdapter对象,它的构造函数允许传入一个logger对象和一个字典。那么接下来,记录日志时,就要使用LoggerAdapter对象而不再是使用logger对象。
下面的代码是一段演示代码,对上面第5章节里的代码稍作修改
import loggingimport jsonfrom logging import LoggerAdapterfrom collections import OrderedDictclass JsonFormatter (logging.Formatter): def __init__ (self, *args, **kwargs ): super ().__init__(*args, **kwargs) self .parse() def parse (self ): self .fields = self ._fmt.split("," ) def format (self, record ): """ 重载format方法,返回json格式字符串 :param record: :return: """ log_record = OrderedDict() print (record.__dict__) for field in self .fields: if field == 'timestamp' : log_record[field] = self .formatTime(record, self .datefmt) else : log_record[field] = record.__dict__.get(field, "" ) log_record = json.dumps(log_record, ensure_ascii=False ) return log_record class LogLevelFilter (logging.Filter): def __init__ (self, name='' , level=logging.INFO ): super ().__init__(name) self .level = level def filter (self, record ): return record.levelno == self .level logger = logging.getLogger('my_log' ) file_handler = logging.FileHandler("test.log" ) file_handler.setLevel(logging.INFO) formater = JsonFormatter(fmt='timestamp,ip,filename,lineno,levelname,msg' , datefmt='%Y-%m-%d %H:%M:%S' ) file_handler.setFormatter(formater) file_handler.addFilter(LogLevelFilter(level=logging.INFO)) logger.addHandler(file_handler) logger.setLevel(logging.DEBUG) la = LoggerAdapter(logger, {"ip" : '123.56.190.188' }) la.debug('debug message' ) la.info('info message' ) la.warning('warn message' ) la.error('error message' ) la.critical('critical message' ) la.error("中文" )
修改主要体现在三处
创建了一个LoggerAdapter对象,扩展了ip信息
创建JsonFormatter对象时,fmt参数增加了ip这个字段
日志输出,不再使用logger对象,而是使用LoggerAdapter对象,其实,la仅仅是对logger对象做了一层包装而已
下面的代码是LoggerAdapter的定义,LoggerAdapter对象的所有操作,其实都是通过self.logger完成的。
class LoggerAdapter (object ): """ An adapter for loggers which makes it easier to specify contextual information in logging output. """ def __init__ (self, logger, extra ): """ Initialize the adapter with a logger and a dict-like object which provides contextual information. This constructor signature allows easy stacking of LoggerAdapters, if so desired. You can effectively pass keyword arguments as shown in the following example: adapter = LoggerAdapter(someLogger, dict(p1=v1, p2="v2")) """ self .logger = logger self .extra = extra
python虚拟环境在开发与生产环境下的使用 任何技术的存在与发展,都是为了解决实际的问题,如果没有这个前提,技术就没有立足之地,python虚拟环境这种技术,就是最好的证明。
1. 第三方库安装在哪里 每当我们使用pip命令安装第三方库时,第三方库都会被安装到python的site-packages目录下,以我的电脑为例,我的python3.6的安装目录为
/Library/Frameworks/Python.framework/Versions/3.6
在该目录下,有一个lib文件夹,继续向下寻找
lib/python3.6/site-packages
python脚本里引用第三方库时,解释器就会到这个目录下寻找第三方库。
如果你并不知道自己的python安装到了哪里,在python交互式解释器中通过sys.path命令就可以获得所使用的python环境
➜ mypro python3 Python 3.6.3 (v3.6.3:2c5fed86e0, Oct 3 2017, 00:32:08) [GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import sys >>> sys.path ['', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python36.zip', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/lib-dynload', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages']
2. 同一个第三方库的不同版本 第三方库不会一成不变,开发者会对它进行升级改造,发布新的版本,而对于使用者来说,就产生了一个小小的麻烦。
我有两个项目,A 和 B,A是一个老项目,B是一个新开发的项目,巧合的是他们都用到了同一个第三方库C,但他们的版本不一致,A项目用的是C1.0,B项目用的是C2.0。
如果C2.0完全兼容1.0,在同一台机器上,我就可以安装好C2.0,这样A和B两个项目都可以正常运行,但如果2.0 不完全兼容1.0,那么安装了2.0 A项目就不能正常运行了,安装了1.0,B项目又不能正常运行,你说说,该咋办。
3. 虚拟环境 在一台机器上,不同的项目需要使用同一个第三方库的不同版本,甚至需要不同的python版本,那么就可以使用虚拟环境技术。
虚拟环境技术将创建不同的环境,在这方面,virtualenv 是非常流行的创建虚拟环境的库。
以下是安装使用过程
3.1 安装 3.2 创建新虚拟环境 mkdir mypro cd mypro virtualenv --no-site-packages venv
第三步,创建出虚拟环境,virtualenv 命令会根据基线环境创建出一个虚拟环境,venv就是虚拟环境所在的目录,这个基线环境如果你不指定,那么virtualenv命令会自己寻找,想要指定的话使用-p 进行设置,以我的电脑环境为例
virtualenv -p /Library/Frameworks/Python.framework/Versions/3.6 --no-site-packages venv
如果你是windows电脑,则可以写成
virtualenv -p c:\Python36\python.exe venv
基线环境要根据你电脑实际安装python的文件夹来定,加上–no-site-packages 这个配置,就表明,基线环境里的第三方库不会被复制到虚拟环境里,这样,虚拟环境就是一个非常干净的环境。
进入文件夹venv ,可以看到3个目录
在bin目录下,有pip,python等可执行程序,在lib/python3.6目录下是标准库文件,也会有site-packages 目录用于存储第三方库。
这个虚拟环境,简直就是基线环境的复制品
3.3 进入虚拟环境 执行上面的命令后,才算是真正的进入到了虚拟环境,现在,如果执行python命令,所使用的就是venv/bin/python, 使用pip3命令,用的也是venv/bin/pip3, 所安装的第三方库,也会被安装到 venv/lib/python3.6/site-packages/ 目录下,这样就实现了项目之间的环境隔离,为每个项目创建一个虚拟环境,安装适合项目的第三方库。
3.4 退出虚拟环境 退出虚拟环境后,所使用的就是基线环境了,在虚拟环境中,除了python环境是隔离的,其他的都是和基线环境相同的。
4. Pycharm自带虚拟环境 pycharm自带虚拟环境了,每创建一个项目,就会为这个项目创建一个虚拟环境,原本是为了方便用户的,但很多初学者对于python的学习还不够深入,因此遇到很多麻烦。
每个项目都可以配置python解释器,当你在pycharm里运行代码时,就是这个python解释器在执行代码,默认使用的是虚拟环境里的python解释器。
但如果你第三方库安装在基线环境下,而你的项目配置的解释器用的虚拟环境的,那么这个第三方库就无法使用了,这个时候你有两个选择,第一个方法是将项目的python解释器修改成基线环境,或者说主环境的python解释器,第二个是通过pycharm在虚拟环境里安装第三方库。
4.1 配置项目的python解释器 按照如下步骤进行配置
先找到preferences
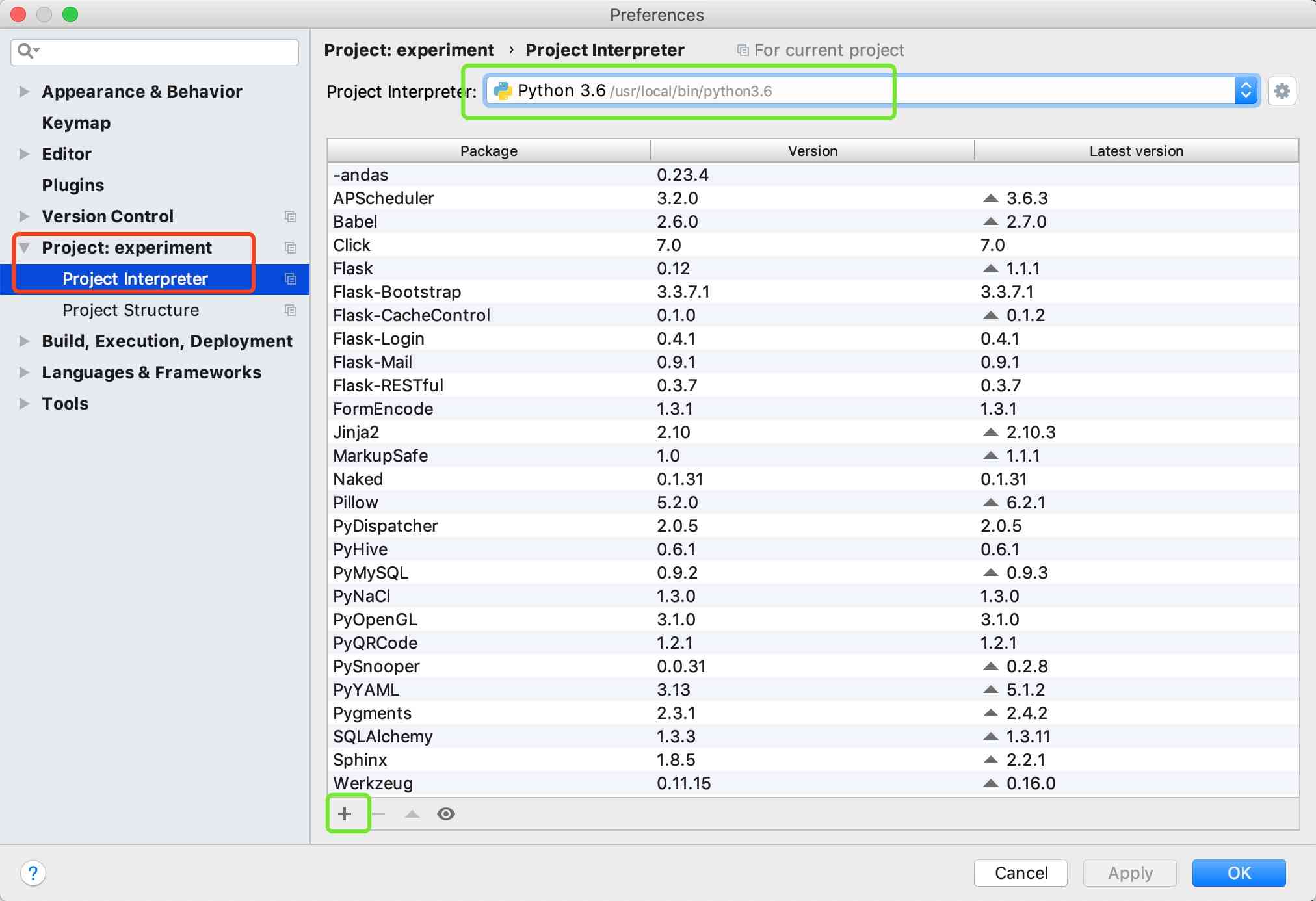
再找到project interpreter ,在右上方配置python解释器。
4.2 通过pycharm安装第三方库 不管解释器配置成哪一个,你都可以通过pycharm来安装第三方库
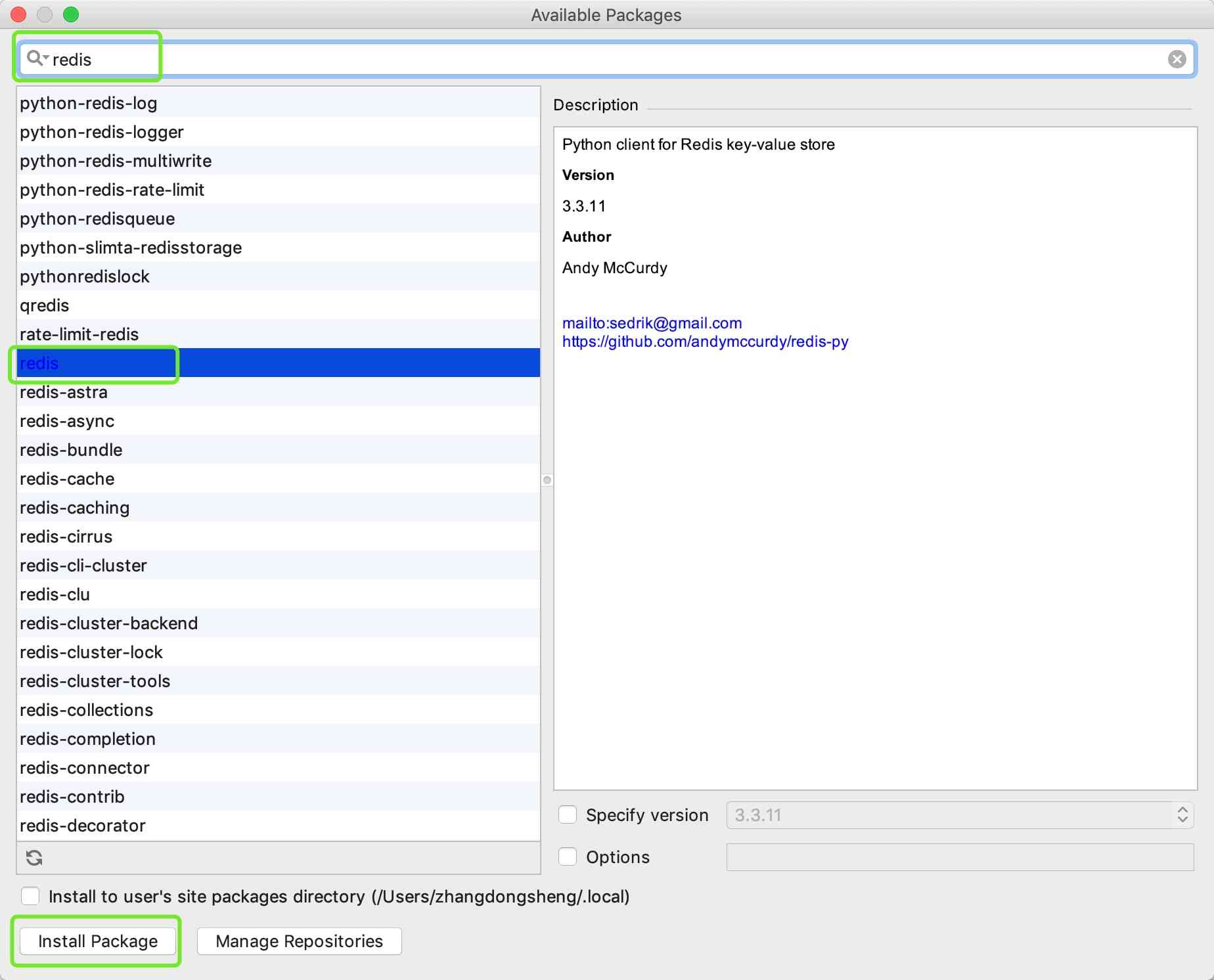
点击上图下部绿色框内的加号按钮,就可以搜索并安装第三方库
在最上面的输入框内输入想要安装的库名称,在备选项里选择想要安装的库,最后点击下方的 Install Package 按钮,就可以完成安装。
python命令行工具click click是一款非常受欢迎的python命令行解析工具,它简单易用,强大又灵活
1. 为何需要命令行工具 我们编写一个具有特定功能的脚本时,通常脚本的输入都是硬编码在代码里的,但如果你实现的是一个比较通用的命令行工具,那么它运行时所需要的参数就不能写死在代码里,不然每次运行时都要修改代码。比如你写了一个获取城市天气信息的脚本,程序的主函数需要城市的名称,你总不能每次运行时都修改脚本里的代码吧。
命令行工具在使用时传入运行所需参数,常见的比如pip,你想安装某个库需要使用
你想卸载某个库,则使用命令
pip就是一个命令工具,它要根据不同的命令参数执行不同的任务。
python标准库提供了Argparse这个命令行解析工具,但着实不好用,此外,你也可以使用sys.argv来临时充当命令行解析工具,但不建议这么做
2. click 使用click可以帮助我们轻松的实现命令行工具
2.1 click.command() 脚本里的函数被click.command()装饰以后,函数就变成了一个命令行工具
import click@click.command() def say_hello (): click.echo('hello' ) if __name__ == '__main__' : say_hello()
运行程序
这样来看,似乎和正常的函数没有什么区别,别着急,继续往下看
2.2 click.option() click.option()可以为工具设置可选参数
import click@click.command() @click.option("-name" , default='world' , help ="姓名" , type =str def say_hello (name ): click.echo('hello {name}' .format (name=name)) if __name__ == '__main__' : say_hello()
执行程序
python3 demo.py -name=lili hello lili
只用click, 很轻松的就传递了参数,不仅如此,还提供了查看文档的功能,执行命令
python3 demo.py --help Usage: demo.py [OPTIONS] Options: -name TEXT 姓名 --help Show this message and exit.
在脚本的后面使用–help参数,就可以获得命令行工具的说明文档
2.3 click.argument 为工具设置必传参数
import click@click.command() @click.option('--count' , default=1 , help ='number of greetings' @click.argument('name' def hello (count, name ): for x in range (count): click.echo('Hello %s!' % name) if __name__ == '__main__' : hello()
再次使用–help命令查看工具文档
Usage: demo.py [OPTIONS] NAME Options: --count INTEGER number of greetings --help Show this message and exit.
你应该注意到,name参数是必传的,你必须像下面这样来执行工具
python3 demo.py --count=2 world Hello world! Hello world!
2.4 click.group() 前面展示的命令工具,都只有一个命令,实际生产中显然是不够用的,click.group()可以让我们把许多命令加到一个组中
import click@click.group() def cli (): pass @click.command() def initdb (): ''' 初始化数据库 :return: ''' click.echo('Initialized the database' ) @click.command() def dropdb (): ''' 删除数据库 :return: ''' click.echo('Dropped the database' ) cli.add_command(initdb) cli.add_command(dropdb) if __name__ == '__main__' : cli()
还可以使用更简单的方法来实现相同的功能
import click@click.group() def cli (): pass @cli.command() def initdb (): ''' 初始化数据库 :return: ''' click.echo('Initialized the database' ) @cli.command() def dropdb (): ''' 删除数据库 :return: ''' click.echo('Dropped the database' ) if __name__ == '__main__' : cli()
我在函数里增加了注释,目的是使用–help命令时可以查看注释
python3 demo.py --help sage: demo.py [OPTIONS] COMMAND [ARGS]... Options: --help Show this message and exit. Commands: dropdb 删除数据库 :return: initdb 初始化数据库 :return:
实际使用
3. 打包 说是命令行工具,但是仍然是用python命令在执行python脚本,想要实现那种直接使用命令的效果,需要将代码打包,以2.4中的代码为例,在demo.py同目录下新建一个setup.py文件,内容为
from setuptools import setupsetup( name='click-example-db' , version='0.1' , py_modules=['cooldb' ], include_package_data=True , install_requires=[ 'click' , ], entry_points=''' [console_scripts] cooldb=demo:cli ''' ,)
name 就是包的名字
version 指定了版本
py_modules 指定了模块名称
entry_points 设置成[console_scripts], 表明要安装成可以在终端调用的命令模块,
cooldb=demo:cli,cooldb是命令,执行该命令时,等同于执行demo.py的cli
最关键的一步了,使用pip进行打包安装
一定要注意editable后面的那个点,千万别落下, 安装过程如下
Obtaining file:///Users/kwsy/kwsy/coolpython Requirement already satisfied: click in /Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages (from click-example-db==0.1) (7.0) Installing collected packages: click-example-db Running setup.py develop for click-example-db Successfully installed click-example-db
Successfully 表示安装成功,现在,就可以像使用pip命令一样使用cooldb命令了
cooldb dropdb Dropped the database cooldb --help Usage: cooldb [OPTIONS] COMMAND [ARGS]... Options: --help Show this message and exit. Commands: dropdb 删除数据库 :return: initdb 初始化数据库 :return:
python创建定时任务 一个很常见的需求,在某天的固定时刻,需要执行某个python脚本来完成特定的任务,面对这样需求,你可能想到的最简单的实现方法是在程序里使用while循环,每次循环使用time.sleep(1),等时间来到规定的时间点就执行某个函数来完成任务,这样的方法可行么?当然可以,只不过太丑陋了。
在linux系统下,你可以使用crontab命令设置定时任务,不多这个命令对于初学者来说用起来不那么简单直观,本文推荐你使用定时任框架APScheduler
该框架的接口定义十分友好,比如你希望你的爬虫函数run_spider 在每天的10点15分能够准时启动,那么你的代码可以写成下面的样子
from apscheduler.schedulers.blocking import BlockingSchedulerdef run_spider (): print ("启动爬虫" ) sched = BlockingScheduler() sched.add_job(run_spider, 'cron' , hour=10 , minute=15 ) sched.start()
在add_job方法里,关于时间的设置,可以参考 CronTrigger类的初始化函数
如果你希望自己的爬虫每3分钟就执行一次爬取,那么你可以将代码写成下面的样子
from apscheduler.schedulers.blocking import BlockingSchedulerdef run_spider (): print ("启动爬虫" ) sched = BlockingScheduler() sched.add_job(run_spider, 'interval' , minutes=3 ) sched.start()
关于时间的设置,可以参考IntervalTrigger类的初始化函数
掌握上面两种定时任务设置方法,搞定绝大多数定时任务已经绰绰有余了
python库打包分发setup.py编写指南 python之所以强大,在于有许许多多的人贡献自己的力量,他们将自己开发的项目打包上传至pypi,这使得python社区有取之不尽用之不竭的第三方库。工作中,你也可以将自己编写的库打包,分享给其他同事,或者在生产环境进行安装部署,本文将教会你如何制作setup.py文件用以打包python库。
setuptools是增强版的distutils,而distutils则是python标准库的一部分,于2000年发布,它能够进行python库的安装和发布,除了setuptools和distutils之外,还有一个distribute,它是setuptools的一个fork分支,弱水三千,只取一瓢,咱们掌握setuptools就可以了。
2. setup.py python打包分发的关键在于编写setup.py文件,咱们来看一下flask的setup.py是如何编写的
import ioimport refrom setuptools import find_packagesfrom setuptools import setupwith io.open ("README.rst" , "rt" , encoding="utf8" ) as f: readme = f.read() with io.open ("src/flask/__init__.py" , "rt" , encoding="utf8" ) as f: version = re.search(r'__version__ = "(.*?)"' , f.read()).group(1 ) setup( name="Flask" , version=version, url="https://palletsprojects.com/p/flask/" , project_urls={ "Documentation" : "https://flask.palletsprojects.com/" , "Code" : "https://github.com/pallets/flask" , "Issue tracker" : "https://github.com/pallets/flask/issues" , }, license="BSD-3-Clause" , author="Armin Ronacher" , author_email="armin.ronacher@active-4.com" , maintainer="Pallets" , maintainer_email="contact@palletsprojects.com" , description="A simple framework for building complex web applications." , long_description=readme, classifiers=[ "Development Status :: 5 - Production/Stable" , "Environment :: Web Environment" , "Framework :: Flask" , "Intended Audience :: Developers" , "License :: OSI Approved :: BSD License" , "Operating System :: OS Independent" , "Programming Language :: Python" , "Programming Language :: Python :: 2" , "Programming Language :: Python :: 2.7" , "Programming Language :: Python :: 3" , "Programming Language :: Python :: 3.5" , "Programming Language :: Python :: 3.6" , "Programming Language :: Python :: 3.7" , "Topic :: Internet :: WWW/HTTP :: Dynamic Content" , "Topic :: Internet :: WWW/HTTP :: WSGI :: Application" , "Topic :: Software Development :: Libraries :: Application Frameworks" , "Topic :: Software Development :: Libraries :: Python Modules" , ], packages=find_packages("src" ), package_dir={"" : "src" }, include_package_data=True , python_requires=">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*" , install_requires=[ "Werkzeug>=0.15" , "Jinja2>=2.10.1" , "itsdangerous>=0.24" , "click>=5.1" , ], extras_require={ "dotenv" : ["python-dotenv" ], "dev" : [ "pytest" , "coverage" , "tox" , "sphinx" , "pallets-sphinx-themes" , "sphinxcontrib-log-cabinet" , "sphinx-issues" , ], "docs" : [ "sphinx" , "pallets-sphinx-themes" , "sphinxcontrib-log-cabinet" , "sphinx-issues" , ], }, entry_points={"console_scripts" : ["flask = flask.cli:main" ]}, )
代码稍稍有点多,直击重点,setup是从setuptools模块引入的一个函数,这个函数有许多参数,正是这些参数对python打包和库安装做出了约定,下表是常用的参数说明
编号
参数
说明
1
name
包名称
2
version
包版本
3
author
作者
4
author_email
作者的邮箱
5
maintainer
维护者
6
maintainer_email
维护者的邮箱
7
url
程序的官网地址
8
license
授权信息
9
description
程序的简单描述
10
long_description
程序的详细描述
11
platforms
程序适用的软件平台列表
12
classifiers
程序的所属分类列表
13
keywords
程序的关键字列表
14
packages
需要打包的包目录(通常为包含 init .py 的文件夹)
15
py_modules
需要打包的 Python 单文件列表
16
download_url
程序的下载地址
17
cmdclass
添加自定义命令
18
package_data
指定包内需要包含的数据文件
19
include_package_data
自动包含包内所有受版本控制(cvs/svn/git)的数据文件
20
exclude_package_data
当 include_package_data 为 True 时该选项用于排除部分文件
21
data_files
打包时需要打包的数据文件,如图片,配置文件等
22
ext_modules
指定扩展模块
23
scripts
指定可执行脚本,安装时脚本会被安装到系统 PATH 路径下
24
package_dir
指定哪些目录下的文件被映射到哪个源码包
25
requires
指定依赖的其他包
26
provides
指定可以为哪些模块提供依赖
27
install_requires
安装时需要安装的依赖包
28
entry_points
动态发现服务和插件
29
setup_requires
指定运行 setup.py 文件本身所依赖的包
30
dependency_links
指定依赖包的下载地址
31
extras_require
当前包的高级/额外特性需要依赖的分发包
32
zip_safe
不压缩包,而是以目录的形式安装
33
python_requires
需要的python版本
下面对几个重要的参数进行讲解
2.1 find_packages find_packages默认在setup.py所在的目录下搜索包含__init__.py文件的目录作为要添加的包,它的函数定义如下
@classmethod def find (cls, where='.' , exclude=('*' , ):
where指定在哪个目录下搜索
exclude设置需要排除的包
include设置要包含的包
在flask的setup.py文件中,find_packages函数第一个参数设置为src,这是因为作者将flask的源码放在了src目录下,src目录下没有__init__.py文件,而src/flask目录下有该文件。
2.2 name name是一个容易错误理解的参数,在flask的setup.py文件中,name的值是Flask, Flask是库的名字,安装以后在使用时,我们需要使用flask,而非Flask
from flask import request
这里的库的名称flask的由来是src/flask这个目录
2.3 python_requires python一直处于发展变化中,尽管做了最大的努力来保证向下兼容,但不同版本间的区别仍然导致第三方库无法在所有版本上运行,因此打包时需指明这个库可以在哪写python版本上运行,当你使用pip安装第三方库时,pip会做版本兼容性检查
2.4 install_requires 安装时需要安装的依赖包,如果你的程序依赖于其他的第三方库,那么你需要在这里指明,当使用pip进行安装时,pip会自动将这些一来的第三方库一起安装
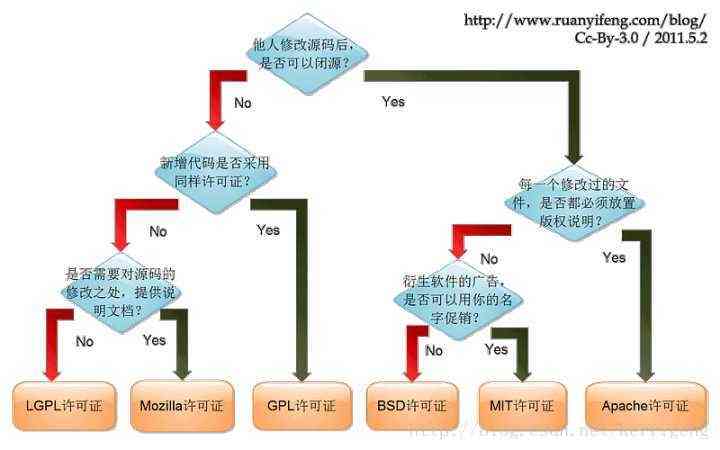
2.5 license 程序的授权信息,开源社区有6种常用的授权协议,下面这张图很好的解释了他们之间的区别
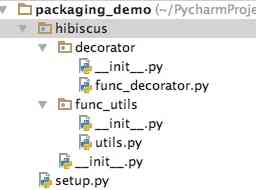
3. 打包分发示例 3.1 新建项目packaging_demo 新建一个项目,项目结构如下
├── hibiscus │ ├── __init__.py │ ├── decorator │ │ ├── __init__.py │ │ ├── __pycache__ │ │ └── func_decorator.py │ └── func_utils │ ├── __init__.py │ └── utils.py └── setup.py
篇幅有限,我只贴出三个文件的代码
3.1.1. packaging_demo/hibiscus/init .py from .decorator import *from .func_utils import *
3.1.2. packaging_demo/hibiscus/decorator/func_decorator.py import timeclass FuncTimeDecorator (object ): def __init__ (self, func ): self .func = func def __call__ (self, *args, **kwargs ): t1 = time.time() res = self .func(*args, **kwargs) t2 = time.time() print ("函数执行时长:" + str (t2 - t1))
3.1.3. packaging_demo/hibiscus/decorator/init .py from .func_decorator import FuncTimeDecorator
3.1.4 setup.py from setuptools import setup, find_packagessetup( name='Hibiscus' , version='0.0.1' , author='酷python' , author_email='pythonlinks@163.com' , description='打包示例' , url='http://www.coolpython.net' , packages=find_packages(), classifiers=[ "Programming Language :: Python :: 3" , "License :: OSI Approved :: MIT License" , "Operating System :: OS Independent" , ], python_requires='>=3.6' , )
3.2 打包 打包之前,先确认所需要的工具是否齐全,主要是setuptools和wheel
python3 -m pip install --user --upgrade setuptools wheel
之后在setup.py所在目录执行下面的命令
python3 setup.py sdist bdist_wheel
打包之后会生成几个重要文件夹,主要关注dist,在这个文件夹下生成了两个文件
Hibiscus-0.0.1-py3-none-any.whl Hibiscus-0.0.1.tar.gz
.whl可以理解为二进制安装包,.tar.gz可以理解为源码安装包,解压后可以看到程序的源码
3.3 安装 安装就比较方便了,在执行完下面的命令后
python3 setup.py sdist bdist_wheel
有多种安装方法
3.3.1 在自己的程序源码里安装 可以直接利用setup.py进行安装
3.3.2 使用.whl文件 也可以进入dist目录,执行下面的命令
pip3 install Hibiscus-0.0.1-py3-none-any.whl
3.3.3 使用tar.gz文件 pip3 install Hibiscus-0.0.1.tar.gz
这种方法先编译出wheel文件,然后再进行安装,如下是其安装过程
Processing ./Hibiscus-0.0.1.tar.gz Building wheels for collected packages: Hibiscus Building wheel for Hibiscus (setup.py) ... done Created wheel for Hibiscus: filename=Hibiscus-0.0.1-py3-none-any.whl size=2382 sha256=e4f46223ac138f0b30c3c7fdad3f3284f964144d35e31188fb3d58761aced350 Stored in directory: /Users/kwsy/Library/Caches/pip/wheels/6f/9f/44/951064df5b5bba5bc41bf713804006c271b2a6946e139dd79c Successfully built Hibiscus Installing collected packages: Hibiscus Successfully installed Hibiscus-0.0.1
3.3.4 解压tar.gz文件然后使用setup.py安装 对tar.gz解压,解压后的文件目录如下
├── Hibiscus.egg-info │ ├── PKG-INFO │ ├── SOURCES.txt │ ├── dependency_links.txt │ └── top_level.txt ├── PKG-INFO ├── build │ ├── bdist.macosx-10.9-x86_64 │ └── lib │ └── hibiscus │ ├── __init__.py │ ├── decorator │ │ ├── __init__.py │ │ └── func_decorator.py │ └── func_utils │ ├── __init__.py │ └── utils.py ├── dist │ └── Hibiscus-0.0.1-py3.6.egg ├── hibiscus │ ├── __init__.py │ ├── decorator │ │ ├── __init__.py │ │ └── func_decorator.py │ └── func_utils │ ├── __init__.py │ └── utils.py ├── setup.cfg └── setup.py
执行命令
注意看dist目录里的Hibiscus-0.0.1-py3.6.egg,就是这个文件被安装到了site-packages目录下。
3.4 使用pip安装和python命令安装的区别 使用python命令进行安装
经过这种方式安装,会将Hibiscus-0.0.1-py3.6.egg文件安装到site-packages目录下,而如果使用pip命令安装,则会在site-packages目录下创建一个名为hibiscus的目录, 在这个目录下有程序的源码。
简单总结,pip安装后可以在site-packages目录下找到源码,而使用python命令直接安装,则只能找到一个.egg文件