python实战练手项目—获取谷歌浏览器的历史记录,分析一个人的上网行为
谷歌浏览器的历史浏览记录存储在名为History sqlite文件中,在mac环境下,该文件的地址是
/Users/zhangdongsheng/Library/Application Support/Google/Chrome/Default/History
|
注意替换用户名(zhangdongsheng)
如果是windows系统,文件的目录为
%LocalAppData%\Google\Chrome\User Data\Default
|
历史浏览记录存储在urls表里,这里只关注last_visit_time和url字段,前者是访问时间,后者是网址。last_visit_time字段存储的是时间是距离1601年1月1日0时0分0秒的微秒数,在windows系统下,FILETIME是从1601-01-01开始计时的,而在unix,linux系统下,则是从1970-01-01开始计时的。
有了数据库和表,就可以直接从数据库文件里读取数据了,读取数据时,一定要把谷歌浏览器关掉,不然它会一直锁着History文件,导致程序无法读取,下面的程序读取19年5月1日之后浏览记录
import sqlite3
from urllib.parse import urlparse
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
db_path = '/Users/zhangdongsheng/Library/Application Support/Google/Chrome/Default/History'
conn = sqlite3.connect(db_path)
sql = '''
select url from urls where
datetime(last_visit_time/1000000-11644473600,'unixepoch')
> '2019-05-01'
'''
cursor = conn.execute(sql)
|
得到的url内容如下
https://www.cnblogs.com/zzqcn/p/3525636.html
|
还需要对url进行解析,提取出网址的域名,并对域名访问次数进行数量统计
parser = lambda u: urlparse(u).netloc
history_dict = {}
for row in cursor:
print(row[0])
url = parser(row[0])
history_dict.setdefault(url, 0)
history_dict[url] += 1
|
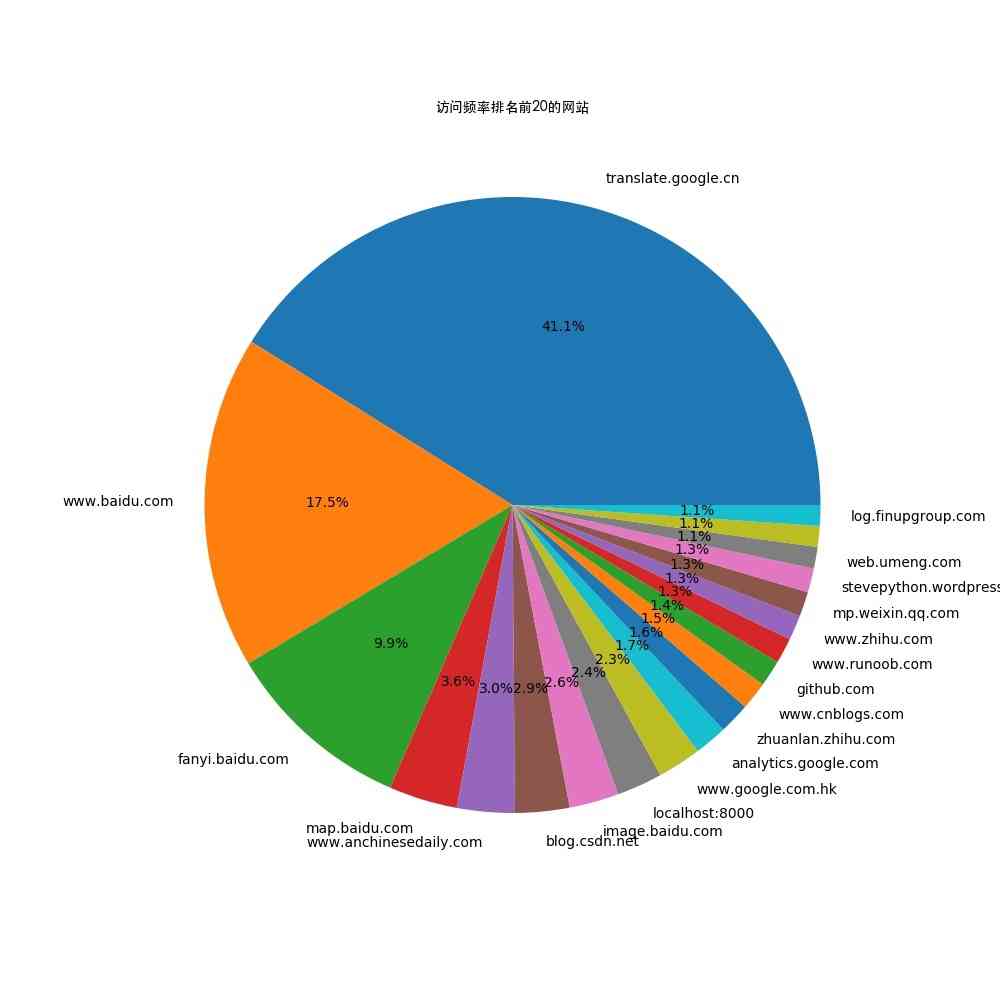
接下来就是可视化呈现的部分了,获取访问频次前20的域名信息并使用matplotlib画出饼图
history_lst = [(url, count) for url, count in history_dict.items()]
history_lst.sort(key=lambda item: item[1], reverse=True)
font = FontProperties(fname='/System/Library/Fonts/STHeiti Medium.ttc')
top_20_url = history_lst[:20]
pie_data = [item[1] for item in top_20_url]
pie_labels = [item[0] for item in top_20_url]
plt.figure(1, figsize=(10, 10))
plt.title('访问频率排名前20的网站', fontproperties=font)
plt.pie(pie_data, autopct='%1.1f%%', labels=pie_labels)
plt.savefig('./浏览频率前20的网站.jpg')
|
生成的图片