TCP导读 TCP协议全称是Transmission Control Protocol,传输控制协议,是一种面向连接的、可靠的、基于字节流的传输层通信协议,由IETF的RFC793定义,进行TCP通信一般由3个步骤组成
创建连接
数据传送
终止连接
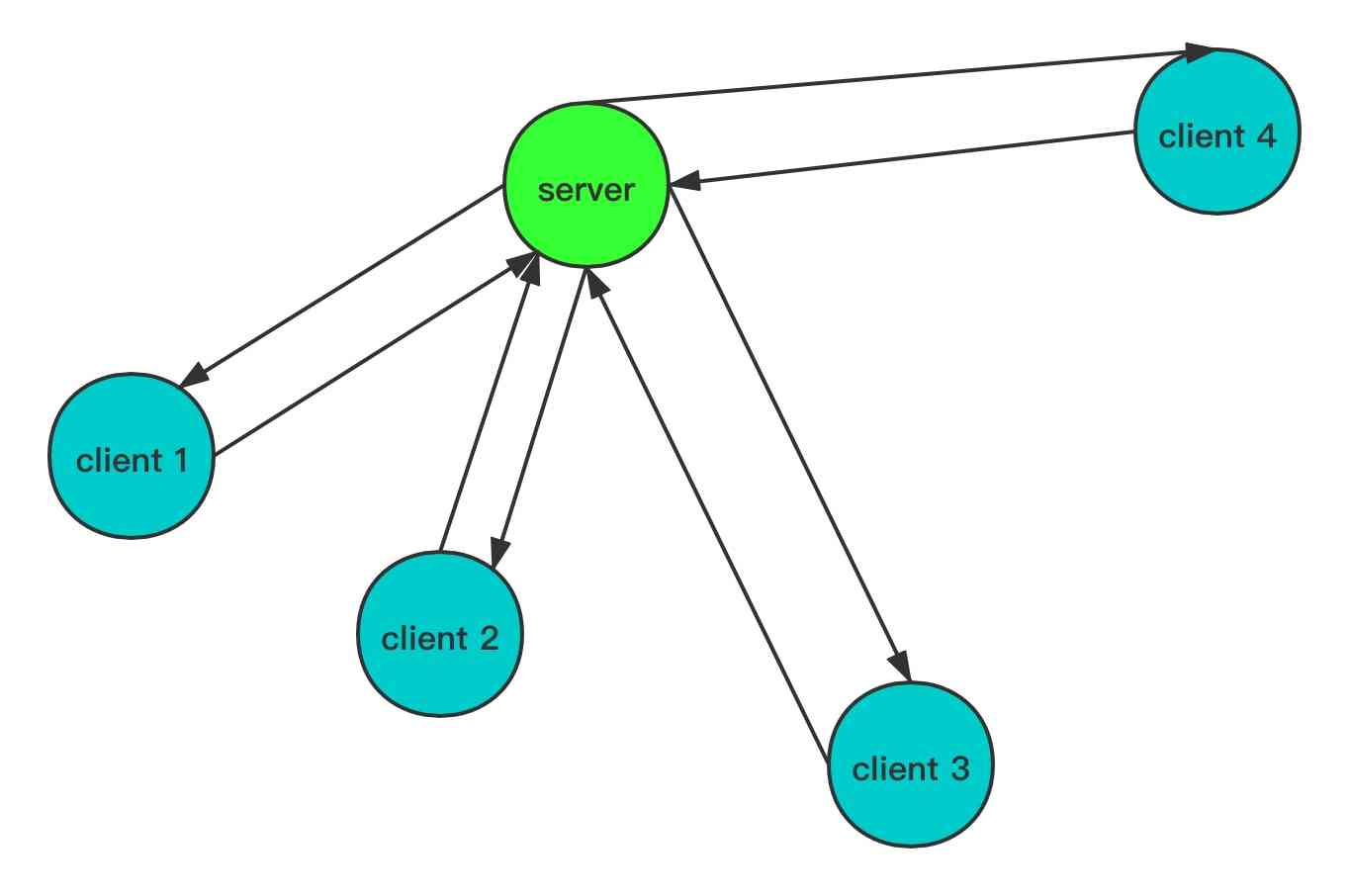
面试的时候,经常被问及的TCP3次握手就发生在建立连接的阶段,下图是TCP客户端与服务端进行通信的示意图
本专题文章如下:
python创建TCP Server
python创建TCP Client
python解决TCP粘包与分包
在TCP server中使用多线程
python socket使用select模型
python scoket使用epoll模型
python创建TCP Server 使用python创建一个TCP Server并不是什么难事,难的是理解每一行代码背后的意义和原理, 涉及到的知识点包括绑定ip, 绑定端口, 监听, 接受一个客户端的连接请求, 接收数据, 关闭连接, 每个步骤都有细节知识点…
import socketserver = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1 ) server.bind(('0.0.0.0' , 8080 )) server.listen(1 ) clientsocket, address = server.accept() data = clientsocket.recv(1024 ) clientsocket.close() server.close()
这样一段代码,有哪些知识需要深入理解呢?
1. SO_REUSEADDR 如果没有下面这行代码
server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1 )
一旦server意外死亡或人为干掉,那么大约两分钟内,无法重新启动该server,这是因为,建立socket连接后,主动断开连接的一方所用的端口会进入到TIME_WAIT状态, 如果短时间内再次启动server,就会引发异常 OSError: [Errno 48] Address already in use
2. 绑定ip server.bind(('0.0.0.0' , 8080 ))
绑定ip写成’0.0.0.0’,表示接受所有ip发起的tcp连接,如果写成127.0.0.1,那么就只接受本机上发出的socket连接了
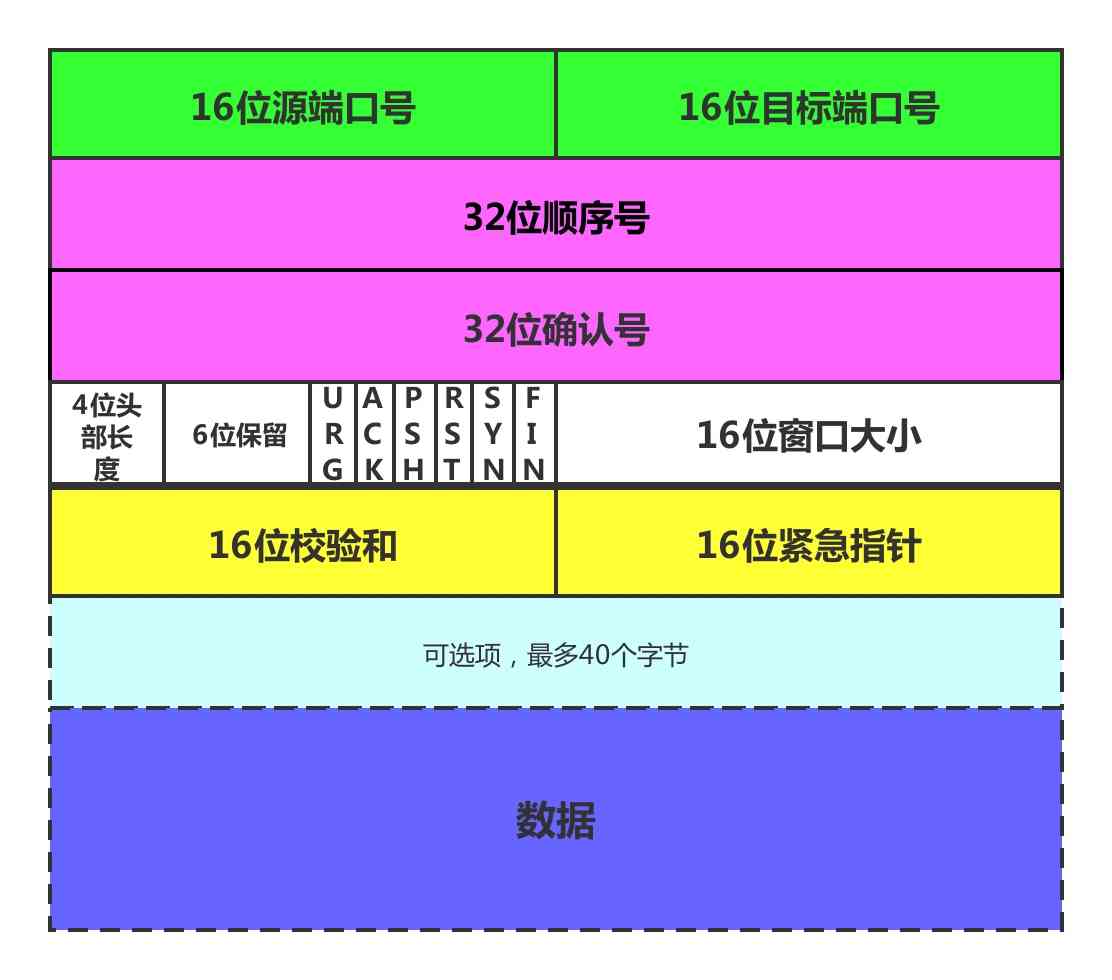
3. 绑定端口 一台主机,可以开放的端口范围是从0~65535,这个范围,是由TCP/IP协议决定的,在该协议中,TCP的头结构如下
端口0在网络编程中有着特殊作用,尤其在unix系统中,如果你申请打开0端口号,0更像是一个统配符,系统会寻找一个合适的端口供你使用,而不是按照你的要求打开端口0。
在TCP/IP 协议中,0端口号是保留的,在TCP和UDP中都不应该使用,1-1023为系统端口,1024-65535为用户端口。
4. 监听 listen方法开始监听客户端连接请求,listen的参数设置为n,并不是表示最多可以建立n个连接,而是在服务器拒绝连接之前,操作系统可以挂起的最大连接数量,我这里设置为1,但可以有多于1个客户端向服务端发起连接。
对于这个参数,tornado默认设置为128,我觉得有点小了,nginx一般推荐大一些,搞个2048也没问题,它是用多个进程进行accept操作,一个进程处理不过来了,会换另一个进程,因此处理的非常快
5.accept accept()接受一个客户端的连接请求,并返回一个新的套接字,这样的解释正确但还不够深入。
作为服务端,系统会维护一个syn队列和一个accept队列,客户端发起连接发送syn包时,系统会把这个连接信息放入到syn队列里,然后返回syn+ack包,等收到客户端最后发回来的ack包时,会从syn队列里把连接信息放入到accept队列里, accept会从accept队列里取连接, 这里的连接都已经完成了3次握手。
6. 接收数据 recv负责接收套接字的数据, 参数设置成1024,并不意味着一定会接收到1024字节数据,即便对方发的数据超过1024,recv执行一次究竟能收到多少数据,取决接收缓冲区里有多少数据以及TCP/IP协议,如果已知对方会发送5000字节的数据,那么我们需要自己统计已经接收了多少,还剩余多少没有收到
7. 关闭连接 我这里用了close(),也可以用shutdown(),但你千万不要以为关闭socket连接有两种方法,其实他们很不同。shutdown破坏了连接,而close只是关闭本进程的socket id,不破坏连接,此时,其他进程仍然可以在该连接上发送和接收消息。前面提到过,nginx使用多个进程进行accept操作,这些进程都是fork出来的,他们共同使用同一个socket连接,如果某一个进程执行close,并不影响其他进程继续使用,每进行一次close,计数器就会减一,等到为0时,就是所有进程都执行close了,此时,套接字资源才会被回收。
python创建TCP Client 1. TCP 客户端与服务端通信
import socketimport timehost = '127.0.0.1' port = 8081 addr = (host, port) client = socket.socket(socket.AF_INET,socket.SOCK_STREAM) client.connect(addr) client.send(b'I am client' ) revcdata = client.recv(1024 ) print (revcdata.decode(encoding='utf-8' ))time.sleep(1 ) client.close()
为了配合客户端测试,同时编写服务端代码
import socketserver = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1 ) server.bind(('0.0.0.0' , 8081 )) server.listen(1 ) clientsocket, address = server.accept() data = clientsocket.recv(1024 ) clientsocket.send('我已经收到' .encode(encoding='utf-8' )) clientsocket.close() server.close()
先启动服务端,然后在另一个终端里启动客户端,客户端与服务端完成一次通信,随后都关闭
2. 客户端代码解读 客户端代码似乎和服务端代码很相似,对比一下有四处不同。
客户端代码没有bind
客户端代码没有listen
客户端代码没有accept
客户端需要connect
2.1 connect 服务端不需要去connect谁,它只需要等待客户端来连接它就可以了,所以客户端必须bind,指定监听的IP和端口,因此,在socket应用程序中,必须先启动服务端,启动后服务端进行listen,客户端发起connect,服务端accept
2.2 bind 客户端其实也能进行bind操作,指明用哪个端口与服务端通信,但通常来说不会这么做,原因很简单,服务端一般来说要一直提供服务,轻易不会停下来,而客户端却可能经常停下来,想想上一篇讲的time_wait,再有,如果客户端的程序是多线程的,多个线程里总不能同时去bind同一个端口吧。所以不bind是最好的,让操作系统来随机分配端口
2.3 send send方法用于发送数据,数据类型必须是bytes类型,字符串与bytes类型之间的相互转换可以参考bytes 字节串
, send函数执行完了,不代表数据已经被发送出去了,函数返回,只是表示这些数据已经被放入到发送缓冲区了,至于何时被发送到网络上,由socket协议自己来决定。
send方法的返回值是本次发送数据的长度,假设你send的数据的长度是1000,send函数执行完了,其返回值可能小于1000,比如返回值是900,这就意味着只有前900个字节的数据被放入到发送缓冲区了,因此在send时,你必须检查send函数的返回值并和你要发送的数据长度做对比,遇到我刚才说的情况,你只好重新发送失败的那部分,可靠的写法类似这样
data = b'I am client' sendlen = 0 while sendlen < len (data): successlen = client.send(data[sendlen:]) sendlen += successlen
2.4 recv 关于recv,虽然参数是1024,但这不代表你就能接收到这么多的数据,这个参数的意思是我想接收1024个字节的数据,但socket协议最终给你的可能比你要求的少,想想也合理,因为TCP是不维护数据边界的,一次给你多少不影响你的分析,但绝不会超过你所要求的,如果缓冲区里有数据了,也没必要非得等到缓冲区的数据长度达到1024再给你。如果recv得到的数据长度是0,那就表示对方已经断开了连接
2.5 分包与粘包 一个tcp包最多可以装1460个字节的数据,所以如果你要发送的数据长度是2000个字节,那么这些数据最少要分成两份,也就是两个TCP包发过去,如果你频繁的发送长度只有10个字节的数据,那么为了不浪费网络带宽,这些大量的长度只有10的数据会被装进同一个TCP包中一起发送过去,这就是TCP的分包与粘包。这个对于接收方来说就是个麻烦,由于TCP自己不维护数据边界,因此应用程序本身必须对此进行处理,以便应对一段完整数据被分多个包发送(分包)和多个小段数据被一起发送(粘包)的情况,下一篇将给出一个非常简单的解决方案
python解决TCP粘包与分包 1. 粘包与分包 一个以太网包只能传输1500字节长度的数据,而这其中,IP头和TCP头各占去了20个字节,因此,有效载荷为1460,如果你要发的一段数据的长度超过了1460,假设为2000,那么必然被分成多个以太网包发送过来,对于接收方来说,如果每次接受1024个字节,则需要多次recv才能把整段数据接收,而TCP是不维护数据边界的,因此对于接收方来说,完全不知道这一段数据什么时候结束。粘包则和分包相反,你要发送的数据长度很短,比如只有30个字节左右,如果你以非常快的速度发送,那么有可能一个以太网包里包含了好几段数据,他们是被一起发送过来的,这时接收方recv得到的数据是好几段数据连在一起,无法分开
2. 简单的解决方案 上面讲的就是TCP的分包和粘包问题。如何解决呢,一种方法就是约定好命令的长度,这样一来,接收方就可以根据提前约定好的数据长度来解析数据了。但这样会产生许多不必要的麻烦了,比如实际发送数据小于约定长度时需要填充,这样也造成了传输上的浪费。
另一种方法就是对要传输的数据进行封装,比如在数据的最前面加上一个长度标识,指明本次要发送的数据长度是多少,这样一来,接收方先获得数据的长度,然后根据数据的长度来获取实际数据。
在数据的前面加一个长度为5的头用来标识数据的长度,假设要发送数据的长度是50,则头就是“00050”,后接实际数据。接收方在获得数据后,先解析前5位,获得数据实际长度后再继续解析后面的数据
3. MsgContainer 实现一个MsgContainer类,客户端使用pack_msg方法封装数据,服务端使用add_data方法将接收到的数据放到自己维护的缓冲区中,根据协议剥离出客户端实际发送的数据
zero_count = 5 class MsgContainer (object ): def __init__ (self ): self .msg = [] self .msgpond = b'' self .msg_len = 0 def __add_zero (self, str_len ): head = (zero_count - len (str_len))*'0' + str_len return head.encode(encoding='utf-8' ) def pack_msg (self, data ): """ 封装数据 :param data: :return: """ bdata = data.encode(encoding='utf-8' ) str_len = str (len (bdata)) return self .__add_zero(str_len) + bdata def __get_msg_len (self ): self .msg_len = int (self .msgpond[:5 ]) def add_data (self, data ): if len (data) == 0 or data is None : return self .msgpond += data self .__check_head() def __check_head (self ): if len (self .msgpond) > 5 : self .__get_msg_len() self .__get_msg() def __get_msg (self ): if len (self .msgpond)-5 >= self .msg_len: msg = self .msgpond[5 :5 +self .msg_len] self .msgpond = self .msgpond[5 +self .msg_len:] self .msg_len = 0 msg = msg.decode(encoding='utf-8' ) self .msg.append(msg) self .__check_head() def get_all_msg (self ): return self .msg def clear_msg (self ): self .msg = []
3.1 封装数据 mc = MsgContainer() data = mc.pack_msg('123' ) print (data)
这是一段封装数据的示例,123被封装成b’00003123’, 前5位表示数据长度,’00003’ 表示数据长度为3,从第6位开始的到第8位是实际数据
3.2 解析数据 mc = MsgContainer() mc.add_data(b'00006\xe4\xb8\xad\xe5\x9b\xbd' ) mc.add_data(b'00015\xe9\x94\x84\xe7\xa6\xbe\xe6\x97\xa5\xe5\xbd\x93\xe5\x8d\x88' ) lst = mc.get_all_msg() for item in lst: print (item)
输出结果
4. 在服务端使用 def start_server (port ): HOST = '0.0.0.0' PORT = port s = socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.bind((HOST, PORT)) s.listen(1 ) mc = MsgContainer() while True : conn, addr = s.accept() print ('Connected by' ,addr) while True : data = conn.recv(2 ) if len (data) == 0 : break mc.add_data(data) msgs = mc.get_all_msg() for msg in msgs: print (msg) mc.clear_msg() conn.close() if __name__ == '__main__' : start_server(8801 )
在服务端使用recv接收数据时,我故意每次调用函数都只接收两个字节的内容以此来验证我的方案是否可行, 启动TCP server, 等待客户端发送数据。 这个服务端使用while循环一直在监听连接请求,客户端的程序可以多次执行。
5. 在客户端使用 import socketmc = MsgContainer() def start_client (addr, port ): s = socket.socket() s.connect((addr, port)) s.send(mc.pack_msg('解决分包问题' )) s.send(mc.pack_msg('酷python' )) s.close() if __name__ == '__main__' : start_client('127.0.0.1' , 8801 )
客户端发送数据前,先使用pack_msg方法封装数据
在TCP server中使用多线程 目前,我所实现的TCP server服务能力都很差,根本无法同时与多个客户端进行交互,只有处理完一个客户端的交互以后才能使用accept等待下一个客户端的连接。
本篇,我将使用多线程技术,在通过accept获得一个socket文件后,启动一个多线程来专门处理这个客户端的数据传输。
1. 服务端代码 import socketimport threadingdef worker (client ): while True : data=client.recv(1024 ) if len (data) == 0 or data == None : break print (data.decode(encoding='utf-8' )) client.send('收到数据' .encode(encoding='utf-8' )) def start_server (port ): HOST = '0.0.0.0' PORT = port s = socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1 ) s.bind((HOST,PORT)) s.listen(1 ) while True : conn, addr = s.accept() print ('Connected by' ,addr) t = threading.Thread(target=worker, args=(conn, )) t.start() if __name__ == '__main__' : start_server(8801 )
在服务端,我使用while实现了无限循环,在循环里使用accept接受TCP连接,获得连接后,这个连接何时将全部数据发送给服务端是未知的,如果一直处理这个连接,那么其他的连接就无法处理,因为在服务端,代码无法执行到下一次accept。使用了多线程以后,情况就不同了,每个TCP连接使用一个线程来处理,那么主线程就可以再次执行到accept这行代码上,不受任何操作的阻塞影响。
2. 客户端代码 import osimport timeimport socketdef start_client (addr, port ): PLC_ADDR = addr PLC_PORT = port s = socket.socket() s.connect((PLC_ADDR, PLC_PORT)) count = 0 while True : msg = '进程{pid}发送数据' .format (pid=os.getpid()) msg = msg.encode(encoding='utf-8' ) s.send(msg) recv_data = s.recv(1024 ) print (recv_data.decode(encoding='utf-8' )) time.sleep(3 ) count += 1 if count > 20 : break s.close() if __name__ == '__main__' : start_client('127.0.0.1' , 8801 )
客户端不需要做什么改变,在代码里,每次发送完消息后,都会sleep 3秒钟,一共发送20次,这样,就有足够的时间启动多个client来测试服务端是否有能力同时处理多个客户端的请求了。
python socket使用select模型 在TCP服务端使用多线程技术能够提高响应的能力,但这种提高是有限的,因为你不可能无限制的创建多线程,更何况python的度线程还受到GIL锁的限制。想要更稳定的提高服务端性能,可以使用select模型。
select模型是多路复用模型的一种,windows和linux下都可以使用,还有更厉害的epoll模型,下一篇将会介绍。select模型允许进程指示内核等待多个事件的任何一个发生,并在只有一个或者多个事件发生或者经历一段事件后select函数才返回。select模型其实很好理解,我们给它三个数组,数组里存放的是socket文件,每一次执行select,模型会从这三个数组中分别挑出来可读的,可写的,发生异常的socket,并分别放入到三个数组中,这样,应用层遍历这三个数组,做相应的操作。
1. 服务端示例 import selectimport socketdef start_server (port ): HOST = '0.0.0.0' PORT = port server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1 ) server.bind((HOST, PORT)) server.listen(10 ) inputs = [server] outputs = [] while inputs: readable, writable, exceptional = select.select(inputs, outputs, inputs) for s in readable: if s is server: connection, client_address = s.accept() inputs.append(connection) else : data = s.recv(1024 ) if data: print (data.decode(encoding='utf-8' )) if s not in outputs: outputs.append(s) else : if s in outputs: outputs.remove(s) inputs.remove(s) s.close() for w in writable: w.send('收到数据' .encode(encoding='utf-8' )) outputs.remove(w) for s in exceptional: inputs.remove(s) if s in outputs: outputs.remove(s) s.close() if __name__ == '__main__' : start_server(8801 )
在select模型中,将server放入到inputs中,当执行select时就会去检查server是否可读,就说明在缓冲区里有数据,对于server来说,有连接进入。使用accept获得客户端socket文件后,首先要放入到inputs当中,等待其发送消息。
1.2 readable select会将所有可读的socket返回,包括server在内,假设一个客户端socket的缓冲区里有2000字节的内容,而这一次你只是读取了1024个字节,没有关系,下一次执行select模型时,由于缓冲区里还有数据,这个客户端socket还会被放入到readable列表中。因此,在读取数据时,不必再像之前那样使用一个while循环一直读取。
1.3 writable 在每一次写操作执行后,都从socket从writable中删除,这样做的原因很简单,该写的数据已经写完了,如果不删除,下一次select操作时,又会把他放入到writable中,可是现在已经没有数据需要写了啊,这样做没有意义,只会浪费select操作的时间,因为它要遍历outputs中的每一个socket,判断他们是否可写以决定是否将其放入到writtable中
1.4 异常 在exceptional中,是发生错误和异常的socket,有了这个数组,就在也不用操心错误和异常了,不然程序写起来非常的复杂,有了统一的管理,发生错误后的清理工作将变得非常简单
2. 客户端 客户端代码与上一篇一致
import osimport timeimport socketdef start_client (addr, port ): PLC_ADDR = addr PLC_PORT = port s = socket.socket() s.connect((PLC_ADDR, PLC_PORT)) count = 0 while True : msg = '进程{pid}发送数据' .format (pid=os.getpid()) msg = msg.encode(encoding='utf-8' ) s.send(msg) recv_data = s.recv(1024 ) print (recv_data.decode(encoding='utf-8' )) time.sleep(3 ) count += 1 if count > 20 : break s.close() if __name__ == '__main__' : start_client('127.0.0.1' , 8801 )
启动服务端后,你可以启动多个客户端来检查效果
python scoket使用epoll模型 select模型虽好,却有一个缺陷,只能对1024个文件描述符进行监视,虽然可以通过重新编译内核获得更大的监视数量,但这样做还不如将目光投向更高级的epoll模型。select模型中,每一次都需要遍历所有处于监视中的文件描述符,判断他们哪个可写,哪个可读,这样一来,你监视的越多,速度越慢,而在epoll模型中,所有添加到epoll中的事件都会网卡驱动程序建立起回调关系,简言之,如果有一个连接可写,那么这个可写的事件就会报告给你,而你不需要挨个询问他们哪个连接可写,哪个连接可读, tornado框架就使用了epoll模型。
强调一点,本文所用代码只能在linux环境下执行,因为只有linux系统支持epoll模型。
1. 服务端代码 import socketimport selectdef start_server (port ): serversocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) serversocket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1 ) serversocket.bind(('0.0.0.0' , port)) serversocket.listen(100 ) serversocket.setblocking(0 ) epoll = select.epoll() epoll.register(serversocket.fileno(), select.EPOLLIN) try : connections = {} while True : events = epoll.poll(1 ) for fileno, event in events: if fileno == serversocket.fileno(): connection, address = serversocket.accept() connection.setblocking(0 ) epoll.register(connection.fileno(), select.EPOLLIN) connections[connection.fileno()] = connection elif event & select.EPOLLIN: data = connections[fileno].recv(1024 ) if data: epoll.modify(fileno, select.EPOLLOUT) else : epoll.modify(fileno, 0 ) connections[fileno].shutdown(socket.SHUT_RDWR) del connections[fileno] elif event & select.EPOLLOUT: clientsocket = connections[fileno] clientsocket.send('收到数据' .encode(encoding='utf-8' )) epoll.modify(fileno, select.EPOLLIN) elif event & select.EPOLLHUP: epoll.unregister(fileno) if fileno in connections: connections[fileno].close() del connections[fileno] finally : epoll.unregister(serversocket.fileno()) epoll.close() serversocket.close() if __name__ == '__main__' : start_server(8801 )
本文所采用的是epoll模型的边缘触发,除此以外,还有一个水平触发。
1.1 events epoll.poll()返回的是所有可操作的文件描述符和事件类型,具体是哪个事件,需要你自己使用if语句逐个进行判断,此外,还需要你自己来保存文件描述符与socket文件之间的映射关系。
1.2 注册 获得客户端连接后,需要将这个socket注册读事件,这样,当这个socket发送数据后,下一次调用epoll.poll()就会获得该socket。
2. 客户端示例代码 客户端示例代码与上一篇一致
import osimport timeimport socketdef start_client (addr, port ): PLC_ADDR = addr PLC_PORT = port s = socket.socket() s.connect((PLC_ADDR, PLC_PORT)) count = 0 while True : msg = '进程{pid}发送数据' .format (pid=os.getpid()) msg = msg.encode(encoding='utf-8' ) s.send(msg) recv_data = s.recv(1024 ) print (recv_data.decode(encoding='utf-8' )) time.sleep(3 ) count += 1 if count > 20 : break s.close() if __name__ == '__main__' : start_client('127.0.0.1' , 8801 )
启动服务端后,同时启动多个客户端,观察实验效果。
unix socket 1. unix socket 如果你熟悉docker,你或许会知道有一个与docker相关的文件,目录为/var/run/docker.sock, docker通过它与其他进程通信,提供了可以操作docker的API接口。这种技术,就是unix Domain Socket, 又称 unix域套接口 , 用于 位于同一台机器(操作系统)的进程间通信。从编程实现上看,它与TCP/IP的socket非常接近,近乎相同,我非常好奇他们之间的区别之处,google了一番,得到下面还算令人满意的答案
Unix套接字:是机器上运行的服务器之间的内部通信过程 IP套接字:更多是外部的,意味着网络上的进程之间进行通信。即使您也可以在内部使用此类型,它通常位于本地主机和远程主机之间。 对于Unix套接字,最好使用它们,因为可以完全避免诸如路由之类的某些操作,因为域套接字知道它们在同一台计算机上执行,这使它们更快,因此如果在同一主机上进行通信,则使其成为更好的选择。 您可以使用以下命令检出计算机的本地unix套接字: netstat -a -p --unix
2. unix socket 服务端 TCP/IP 在创建服务端socket时,需要指定ip和端口号,unix socket 用于同一台机器之间的通信,只需要一个本地文件就可以了,但这个文件在创建socket之前不能存在,否则会报错,因此,需要事先删除。在创建socket套接字时,要使用socket.AF_UNIX,其余的代码,与创建TCP/IP socket几乎相同
import osimport socketserver_address = './uds_socket' try : os.unlink(server_address) except OSError: if os.path.exists(server_address): raise server = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM) server.bind(server_address) server.listen(1 ) clientsocket, address = server.accept() data = clientsocket.recv(1024 ) print (data)clientsocket.close() server.close()
3. unix socket client 实现一个unix socket 客户端也并非难事
import osimport socketserver_address = './uds_socket' sock = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM) try : sock.connect(server_address) except socket.error as msg: print (msg) sys.exit(1 ) sock.send(b'hello world' ) sock.close()