代码质量导读
如何保证代码质量,是一个永恒的话题。开发人员必须时刻与自身的懒惰对抗,人们总是不由自主的写出烂代码,并总是能找到一个合理的接口为自己开脱,最常用的理由是先保证项目上线,优化的事情以后再说。
事实上,所有的以后再说都会被遗忘,烂代码会逐渐侵蚀整个项目,直到项目变的难以维护。本章将和你讨论如何写出高质量的代码,如何对代码进行单元测试,在代码出现bug时如何调试
python避免代码过度嵌套
代码嵌套让代码变得难以阅读,尤其当嵌套层次超过3层以后,嵌套的太多不符合python扁平胜于嵌套的编程理念,那么怎么才能减少代码的嵌套呢?
1. 使用生成式
tmp = [4, 2, 1, 5, 7] |
从列表tmp中找出大于3的数据,可以使用for循环来完成
tmp = [4, 2, 1, 5, 7] |
这样编写代码没有问题,但不够pythonic,你可以使用列表生成式让代码更简单,而且没有嵌套
tmp = [4, 2, 1, 5, 7] |
2. 三元表达式
python没有三元表达式,但可以借助if else 来实现
a = 5 |
这段代码里,a的值决定了b的值, 我使用if else 语句来编写,出现了嵌套,为了减少嵌套,可以用下面的方法
a = 5 |
代码瞬间变得清爽了许多
3. 优化条件表达式
lst1 = [1, 2, 6, 4, 7, 8, 9] |
编写算法,从两个列表中各取出一个数值,如果两个数值都大于5且他们的和是15,则输出这两个数值
下面向你展示一个非常糟糕的写法
lst1 = [1, 2, 6, 4, 7, 8, 9] |
虽然程序的逻辑是正确的,但是形成了太多的嵌套语句,使得代码难以阅读,下面是修改后的
lst1 = [1, 2, 6, 4, 7, 8, 9] |
如何写出符合python之禅的代码
1. python之禅
在交互式解释器里输入指令
import this |
便可得到python之禅
The Zen of Python, by Tim Peters |
网络上有很多翻译的版本,我比较喜欢下面这个版本
Python之禅 by Tim Peters |
2. 如何理解和应用
网上能够找到的文章,千篇一律的翻译了原文而已,最多是加上一些自己的解读,却让人看的云里雾里,并没有实际的例子可以供读者学习理解。
在收集了查阅了一些技术文章后,我决定综合各路大神的见解加上我个人的一些看法,结合着具体例子来阐释python之禅的含义,个人能力有限,如文章观点有纰漏之处,欢迎你讨论指正。
2.1 明了胜于晦涩
下面用两种方式向百度发送一个get请求
方法1, 使用urllib库
import urllib.request |
方法2,使用requests库
import requests |
对比两段代码不难发现,第二段代码的代码意图更加明显,明确指明了要发送get请求,而第一段代码呢,你无法从代码里直观的观察出是在发送get请求
2.2 简洁胜于复杂
仍然使用urllib库和requests库进行对比,下面两段代码都是发送post请求
1、使用urllib
import urllib.parse |
2、 使用requests
import requests |
对比两段代码,简洁程度高下立判,任何一个技术人员都倾向于选择后者作为自己的努力方向,没有人愿意阅读并维护一大段啰里啰嗦的代码。
2.3 可读性很重要
2.3.1 简单就好
如果你的代码是简明的,简洁的,那么代码就已经具备了可读性了,但这还不够,还有许多可以改进的地方,比如下面的这段代码
for i in range(len(lst)): |
通过索引访问列表元素在语法上没有问题,但阅读时不免觉得代码有些繁琐,下面的代码的可读性就强一些
for i in lst: |
2.3.2 变量命名
python在声明变量时,不需要指明变量的类型,在接触python之前,我的主力语言是c++, 刚接触python时,对这种变量创建方式很不习惯,其他语言,很容易顺藤摸瓜找到变量声明的地方确认变量的类型,而python则不行,所以,我习惯性的在变量名称中加上类型的标识,比如下面这样
name_lst = ['小明', '小红'] |
除了像age,count这样明显表示int类型数据的变量,我喜欢用 “i_” 开头, 表示它是int类型的数据,我认为这样做可以增强代码的可阅读性。
2.3.3 代码注释
说道可阅读性,就不得不说代码注释,我个人非常喜欢给代码添加注释,我希望代码的维护者能知道这段代码的意图,而不是在维护代码时不敢修改,生怕产生连锁bug。好的注释,要解释代码做了什么,如果有必要,还要解释为什么要这样做,这对于维护者修改代码是非常有帮助的。
2.4 扁平胜于嵌套
for循环,while训话,if语句,这些都会产生嵌套,每产生一层嵌套,就会产生一次缩进,最终,就会产生类似下图的代码
据说这是Spring的一段源码,之前还有新闻说,一个程序员在工作群里贴出这段代码被开除。
嵌套最好控制在3层以内,太多了,你自己看着都会烦。
2.5 间隔胜于紧凑
一行代码里,不要做太多的事情,这样做,带给人一种错觉,好像这样可以加快代码的执行速度,实际上是不可能的。
下面是一段紧凑的例子
def func_1(a, b): |
函数func 看起来很简洁,但实际上并不利于阅读,这一行代码里有一次if条件判断,决定执行两个函数中的哪一个,我自己很不喜欢这种方式,我会这样来写
def func(a, b): |
前面是从一行代码的逻辑复杂程度来阐述间隔胜于紧凑的,从代码排版上来说,我喜欢在for循环,while循环,if条件语句前面加上一个空行,因为在这些语句之前,通常来说都是准备数据的代码,这些语句块结束后,也放一个空行,这样代码看起来就会显得错落有致,不至于乱糟糟的黏糊在一起。
优美胜于丑陋,啥是优美呢,这是个哲学问题,每个人对于美的理解是不一样的,但总的来说,工整总归是比混乱美一些,这种代码排版上的用心会产生工整美。
2.6 不要包容所有错误
类似下面的代码,你肯定见过很多
try: |
这种写法的一个好处就是,写代码的人,根本不需要关心代码里面发生了什么异常,来一个终极捕获,万事大吉了,剩下的事情就是记录异常信息。
这中写法有什么问题么,至少在实践中,我还没有遇到什么严重的问题,但我自己也很清楚,这样做是极不合理的,原因在于,自己写的代码,自己都不清楚可能会有什么异常产生,这不就等于像世人宣告,自己不了解自己写的代码么?
如果你了解自己的代码,怎么可能不知道可能发引发哪些异常呢?你辩解说,那么多异常,谁知道会发生什么呢,可是你是技术人员,经验的积累难道还不足以让你评估代码潜在的异常么?胡子眉毛一把抓式的捕获异常,并不能够让我们更加了解自己的程序,也不能让我们提高对代码的掌控能力,除了在时间紧任务重时帮我们快速完成工作外,这种做法不能带来任何其他收益。
3. 写在最后
本文尝试结合实际例子阐述python之禅,但能力有限,总感觉有些力不从心,写在最后,是想感慨一下,国内技术人员的心态真的不如国外,你能搜索到的文章,都是在翻译python之禅,却鲜有人举例说明,认真研究一下,就这么难么?
当然,你可以说这都是房价太高导致的,人人都在想着怎么赚钱,哪有心思踏踏实实做学问啊,哎,我没有买房子,我只是想写一些有价值的东西,写别人懒得较真,懒得打破砂锅问到底的东西,希望我可以坚持下去。
2.1,2.1 小节的内容,参考了http://codingpy.com/article/designing-pythonic-apis/ 的文章内容,文章原文是以色列的一名python开发者所写,标注出处,是因为不想窃取别人的翻译成果。
python项目无用代码检查
需求总是在变化,代码总是在修改,项目总是在重构,如果你不认真维护自己的项目,让糟糕的代码积累的越来越多,迟早有一天会积重难返。修改代码或者重构过程中,经常会出现这样的情况,一些函数已经不再使用了,但是出于某种原因,这些代码没有被删除,而是被保留了下来。随着时间的积累,这样的代码会原来越多,这为后来的人维护代码造成了不必要的麻烦,因此,你需要经常清理那些无用的代码。
说起来简单,做起来却不容易,从一个大的项目里找出明确不再使用的函数并不是一件容易的事情,好在万能的开源社区提供了一款第三方工具—dead, 使用pip来安装
pip install dead |
这个工具需要配合git来使用,它首先使用git ls-files命令来获取所有的文件,然后逐一进行检查,将每一个文件编译成字节码,寻找定义和引用,如果最终找不到引用,就会给出提示
kwsy@zhangdongshengdeMacBook-Air:~/kwsy/coolpython$ dead |
这是在我自己项目里实验的结果,那些只有定义却没有被调用执行的函数都会被检查出来,虽然大部分都是正常的代码。
据作者自己所言,他是在飞机上画了15分钟完成的这个项目,好吧,老外就是牛逼。它还不是一个完美的项目,个别时候还会出现误报,但是那些真正的只有定义而没有调用的函数都会被检查出来,这样可以帮助你寻找项目里的死代码。
使用black模块格式化python代码
初学者很难理解为什么要关注代码质量,对于进阶者来说,你的注意力应当从关注语言基础语法和特性逐渐向软件工程方面进行转移,提升你的能力层次所需要的不仅仅是更高深的python语言知识,还包括你驾驭工程项目的能力。
black是一款非常霸道的代码格式化工具,当它检测到不合格的代码时,会直接帮你修改,甚至不询问你的意见。比如下面的代码
a=4 |
直观的看,没有任何语法问题,但是它并不符合PEP8规范,pycharm会自动检测代码格式并给出修改建议,然而仅仅是建议,你可以不去理会它,如果大家编写的代码都不遵守PEP8规范, 上万行丑陋的代码拥挤在一起,堆砌出的必然是一个垃圾程序,好了,让我们用black来解决这一切
pip3 install black |
使用时,只需要在black 命令后面指定需要格式化的文件或者目录
~/kwsy/coolpython$ black demo.py |
使用起来是不是很方便呢,格式化以后的代码如下
a = 4 |
相比于之前的代码,有两处改变:
- 赋值语句的等号两侧各增加一个空格
- 函数定义前与上一条语句之间保留两个空行
很多编程人员对乔布斯无比追捧,但他们未必在工作中践行乔布斯的理念—美就是生产力,作为一个python开发人员,我们应当践行这一理念,python之襜正是对这一理念的具体践行方法。
使用ipdb调试python程序
在python基础教程中,有一篇文章专门介绍如何使用pycharm内置的调试器来调试代码,如何调试程序,能使用pycharm的调试器固然很好,然而很多场景下,却不具备这样的条件。比如所使用的编辑器是Sublime Text,或者Vim, 一些身经百战的开发人员会使用print语句通过输出变量内容的方式进行调试。
在那些无法使用编辑器内置调试器的场景下,我建议你使用ipdb来调试你的代码。ipdb可以看做是python内置调试器pdb的增强版本,依赖于IPtyhon,提供了补全、语法高亮等功能,使用pip来安装
pip install ipdb |
1. 设置断点
你可以直接在程序里设置断点
import ipdb |
执行程序,会在断点出停下来,进入到调试界面,类似这样的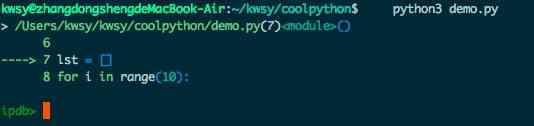
在代码中通过ipdb.set_trace()来设置断点并不是唯一的方式,而且我不建议你这样做,原因在于调试完成以后,你不得不再去删除这行代码,推荐你使用交互式的命令式调试, 将上面代码中和ipdb有关的代码去掉
import random |
在终端里执行命令
python3 -m ipdb demo.py |
进入调试界面后输入
----> 1 import random |
命令b是设置断点,b 8 表示在第8行设置断点,c命令一直执行至断点处。在断点出,你可以随意的查看变量的值,甚至可以修改变量的值.
2. 命令介绍
2.1 h
h是帮助命令,可以列出所有的命令
ipdb> h |
你想知道某个具体命令的作用,可以使用h command来查看
ipdb> h cl |
对于英语稍差点的同学,这可能是一个困难
2.2 断点相关命令
关于b 命令,前面已经做了介绍,该命令默认在当前脚本里执行,如果你想在别的脚本里设置断点,则需要提供脚本的名称
b file_name:line_number |
file_name必须在sys.path中,当前目录默认在sys.path, 你也可以通过..来引用上一层目录
已经设置过的断点在重新运行debug程序时仍然保留,你可以使用disable关闭这些断点,使用enable打开这些断点,如果想清楚,可以使用clear或者cl命令
2.3 执行代码
c命令会执行到下一处断点, s(step) 和 n(next)会逐行执行代码,遇到函数时,s会进入到函数内部,而n命令不会。进入到函数以后,a命令可以查看函数的入参,r可以直接执行到return语句
2.4 忽略某个代码段
j line_number 可以忽略某段代码,下一步直接从 line_number 开始执行
2.5 查看源码
调试界面里默认是当前往后 11 行,这样可能会影响你的调试,使用l或者ll命令可以查看源码,l是查看整个源码,你可以指定某一行代码,也可以指定一个范围 l 5, 10,这样就只看5到10行的代码
2.6 重启或退出
调试过程中,如果你想重新开始,可以使用restart命令或者run命令,但是要注意,此前设置的断点都生效,如果你想要一个全新的调试,使用命令 q、quit 或 exit 退出,然后重新启动debugger
谷歌开源项目风格指南—python代码规范
1. 不要使用分号
永远不要在代码的末尾使用分号,也不要用分号将两条命令放在一行
a = 4 ; b = 5 |
这样的代码可以被执行,但是建议你不要这样做
2. 每行不超过80个字符
一行代码的长度过长,影响阅读,因此建议每行代码长度不要超过80个字符,对于那些确实很长的语句,可以采用适当的方法换行
2.1 长字符串
text = "如何保证代码质量,是一个永恒的话题。开发人员必须时刻与自身的懒惰对抗,人们总是不由自主的写出烂代码," \ |
使用反斜杠的确可以连接一个长字符串,但谷歌的风格指南里建议你使用使用圆括号来实现隐式行连接
text = ("如何保证代码质量,是一个永恒的话题。开发人员必须时刻与自身的懒惰对抗,人们总是不由自主的写出烂代码" |
2.2 参数很多的函数
def test(name, age, _class, score, address, phone, |
不论是定义函数还是调用函数时,如果参数太多导致一行代码字符串数量过多时都可以用这种方法规避。
3. 要过度使用括号
除非是用于实现行连接, 否则不要在返回语句或条件语句中使用括号
3.1 函数返回多个结果时不需要使用括号
def test(x): |
函数返回多个结果时会自动封包成元组,不需要使用括号, 下面的操作毫无必要
def test(x): |
3.2 条件语句
a = 5 |
下面的代码是错误的使用
a = 5 |
4. 缩进
一次缩进4个空格,注意不要使用tab来代替空格,更不能tab和空格混合使用
5. 空行
函数或者类之间要空两行。方法定义之间,类定义与第一个方法之间空一行, 函数和方法内部,你可以根据自己的习惯在你觉得合适的位置上空一行
def func1(): |
6. 空格
- 括号内不要有空格
- 不要在逗号, 分号, 冒号前面加空格, 但应该在它们后面加(除了在行尾).
- 参数列表, 索引或切片的左括号前不应加空格
- 在二元操作符两边都加上一个空格, 比如赋值(=), 比较(==, <, >, !=, <>, <=, >=, in, not in, is, is not), 布尔(and, or, not)
- 不要用空格来垂直对齐多行间的标记
下面是一些错误使用空格的示例
print( 1 ) # 括号里有空格 |
7. Shebang
大部分python文件都不必以#!作为文件第一行的开始,程序的主文件才有必要使用#!/usr/bin/python2或者 #!/usr/bin/python3开始, #!先用于帮助内核找到Python解释器, 但是在导入模块时, 将会被忽略。
8. 注释
8.1 模块
每个文件应该包含一个许可样板. 根据项目使用的许可(例如, Apache 2.0, BSD, LGPL, GPL), 选择合适的样板
8.2 函数和方法
一个函数必须要有文档字符串, 除非它满足以下条件:
- 外部不可见
- 非常短小
- 简单明了
文档字符串应该包含函数做什么, 以及输入和输出的详细描述. 通常, 不应该描述”怎么做”, 除非是一些复杂的算法. 文档字符串应该提供足够的信息, 当别人编写代码调用该函数时, 他不需要看一行代码, 只要看文档字符串就可以了. 对于复杂的代码, 在代码旁边加注释会比使用文档字符串更有意义.
关于函数的几个方面应该在特定的小节中进行描述记录, 这几个方面如下文所述. 每节应该以一个标题行开始. 标题行以冒号结尾. 除标题行外, 节的其他内容应被缩进2个空格.
Args:
列出每个参数的名字, 并在名字后使用一个冒号和一个空格, 分隔对该参数的描述.如果描述太长超过了单行80字符,使用2或者4个空格的悬挂缩进(与文件其他部分保持一致). 描述应该包括所需的类型和含义. 如果一个函数接受foo(可变长度参数列表)或者**bar (任意关键字参数), 应该详细列出foo和**bar.
Returns: (或者 Yields: 用于生成器)
描述返回值的类型和语义. 如果函数返回None, 这一部分可以省略.
Raises:
列出与接口有关的所有异常.
def fetch_bigtable_rows(big_table, keys, other_silly_variable=None): |
8.3 类里的注释
类应该在其定义下有一个用于描述该类的文档字符串. 如果你的类有公共属性(Attributes), 那么文档中应该有一个属性(Attributes)段. 并且应该遵守和函数参数相同的格式.
class SampleClass(object): |
8.4 块注释和行注释
最需要写注释的是代码中那些技巧性的部分. 如果你在下次 代码审查 的时候必须解释一下, 那么你应该现在就给它写注释. 对于复杂的操作, 应该在其操作开始前写上若干行注释. 对于不是一目了然的代码, 应在其行尾添加注释.
# We use a weighted dictionary search to find out where i is in |
为了提高可读性, 注释应该至少离开代码2个空格.
另一方面, 绝不要描述代码. 假设阅读代码的人比你更懂Python, 他只是不知道你的代码要做什么
9. 类
如果一个类不继承自其它类, 就显式的从object继承. 嵌套类也一样.
class Stu(object): |
继承自 object 是为了使属性(properties)正常工作, 并且这样可以保护你的代码, 使其不受 PEP-3000 的一个特殊的潜在不兼容性影响. 这样做也定义了一些特殊的方法, 这些方法实现了对象的默认语义, 包括
__new__, __init__, __delattr__, __getattribute__, __setattr__, __hash__, __repr__, and __str__ |
10. 字符串
避免在循环中用+和+=操作符来累加字符串, 因为字符串是不可变对象,每一次的累加操作都会产生一个新的字符串,作为替代方案, 你可以将每个子串加入列表, 然后在循环结束后用 .join 连接列表,也可以将每个子串写入一个 cStringIO.StringIO 缓存中。
但对于简单的两个字符串之间的连接操作,直接使用+连接就可以,没有必要也使用%或者format方法格式化。
11. 文件和sockets
在文件和sockets结束时, 显式的关闭它,如果不关闭,会导致非常严重的问题,而且很难排查,你可以使用with关键字来管理文件
with open("hello.txt") as hello_file: |
with语句块结束时,会帮你关闭文件
12. TODO注释
为临时代码使用使用TODO注释,或者标注将来做某件事情,TODO注释应包含括号括起来的作者的名字,在一个可选的冒号后面添加注释,解释要做什么,如果可以,请加上一个日期
# TODO(kwsy): 2020年1月10日完善Stu的细节 |
13. 导入格式
每个导入应该独占一行,不要在一行导入里导入多个模块
导入总应该放在文件顶部, 位于模块注释和文档字符串之后, 模块全局变量和常量之前. 导入应该按照从最通用到最不通用的顺序分组:
- 标准库导入
- 第三方库导入
- 应用程序指定导入
每种分组中, 应该根据每个模块的完整包路径按字典序排序, 忽略大小写.
import foo |
14. 语句
每个语句应该独占一行
15. 访问控制
这一点,可能重视封装的面向对象程序员看到这个可能会很反感,对于那些频繁访问使用又不太重要的属性,不妨使用公有属性来替代,这样就避免了添加大量set_xxx和get_xxx方法,我建议你使用property属性,既能像使用公有属性那样方便,又能保证属性的安全性。
16. 变量命名
16.1 应该避免的名称
- 单字符名称, 除了计数器和迭代器.
- 包/模块名中的连字符(-)
- 双下划线开头并结尾的名称(Python保留, 例如__init__)
16.2 命名约定
- 所谓”内部(Internal)”表示仅模块内可用, 或者, 在类内是保护或私有的.
- 用单下划线(_)开头表示模块变量或函数是protected的(使用from module import *时不会包含).
- 用双下划线(__)开头的实例变量或方法表示类内私有.
- 将相关的类和顶级函数放在同一个模块里. 不像Java, 没必要限制一个类一个模块.
- 对类名使用大写字母开头的单词(如CapWords, 即Pascal风格), 但是模块名应该用小写加下划线的方式(如lower_with_under.py). 尽管已经有很多现存的模块使用类似于CapWords.py这样的命名, 但现在已经不鼓励这样做, 因为如果模块名碰巧和类名一致, 这会让人困扰.
Python之父Guido推荐的规范
| Type | Public | Internal |
|---|---|---|
| Modules | lower_with_under | _lower_with_under |
| Packages | lower_with_under | |
| Classes | CapWords | _CapWords |
| Exceptions | CapWords | |
| Functions | lower_with_under() | _lower_with_under() |
| Global/Class Constants | CAPS_WITH_UNDER | _CAPS_WITH_UNDER |
| Global/Class Variables | lower_with_under | _lower_with_under |
| Instance Variables | lower_with_under | _lower_with_under (protected) or __lower_with_under (private) |
| Method Names | lower_with_under() | _lower_with_under() (protected) or __lower_with_under() (private) |
| Function/Method Parameters | lower_with_under | |
| Local Variables | lower_with_under |
17. main
在Python中, pydoc以及单元测试要求模块必须是可导入的. 你的代码应该在执行主程序前总是检查 if name == ‘main‘ , 这样当模块被导入时主程序就不会被执行.
def main(): |
为你的函数起一个好的名字
没有人不希望为自己的孩子起一个好听的名字,要有好的寓意,要听起来顺耳,要与众不同,你的函数,也应该如此。好的函数命名,可以让使用者大致理解其功能,依据经验推理出应当传入什么样的参数,反之,坏的函数命名,就让人摸不到头脑甚至容易误导使用者。
最近,就遇到了这样一件事情。一个同事在使用jieba分词时,错误的使用了load_userdict函数来加载自定义词典。从根本上讲,没有认真阅读jieba的技术文档是导致错误使用该函数的主因,但这个函数的命名所产生的误导也不容忽视。
load_userdict只有一个参数,见到这个函数的第一反应,大多数人想到的是这个参数应当传入一个字典类型的数据,如果你也是这样,那么恭喜你,入坑了。如果你真的传入一个字典,这个函数不会报任何错误,甚至整个程序都会正常运行,这究竟是怎么一回事呢?
1. file-like object
让我们来看一下jieba维护者为这个函数添加的注释
def load_userdict(self, f): |
参数f 可以是文件的地址, 也可以是一个file-like object。如果是文件地址,则函数会使用open函数打开,这里有必要对file-like object做一下解释,在python中,如果一个对象实现了read() 和 write(), 那么它就是一个file-like object, 例如StringIO对象,建立起连接的socket对象,他们都是file-like object。
2. 传入一个字典
load_userdict,如果你没有认真看说明文档,而是凭借函数名称对函数的功能和参数类型进行揣测,那么,你很容得出函数接收字典类型参数的结论。更容易误导使用者犯错误的是,如果你真的传入一个字典,函数不会报错,加载的字典甚至可以”正常“使用。原因在于,函数内部并没有对传入参数的类型进行检查。
获取是由于巧合,尽管没有对参数类型进行检查,程序却可以正常执行而不报错,函数里对字典进行enumerate操作,是不会报错的,但由于数据格式的问题,不能正确解析一个词的freq和tag,下面这段代码可以正确运行,但是但每一个词的freq将会丢失
import jieba |
我的这位同事对这个函数的命名颇有微词,并且坚持认为应该允许以字典的方式加载自定义词典,后来,我给了他一种变通的方法
import jieba |
尽管这样做也违背了这函数对参数的要求,但是可以正常加载自定义词典
3. 建议修改这个函数名称
鉴于这个函数的名称具有误导性,我建议对名称进行修改
def load_userdict_file(self, f): |
这样一来,大家都会明白这个函数需要传入的是一个file文件,具体是文件的路径,还是文件对象,有了这样的函数名称,自然会引导大家来查看技术文档。另一方面,在函数内对参数类型进行检查,如果是字符串,则判断文件路径是否存在,如果是文件对象,则直接使用。
如何写出优质的python代码
如何写出优质的python代码
- 命名要有意义
- 1.1 见其名,而知其意
- 1.2 避免误导
- 1.3 避免太短,或是太长
- 1.4 避免在名称后面加数字
- 函数或方法要安全,简洁
- 2.1 单个函数代码行数不应过多
- 2.2 功能要单一,只做一件事情
- 2.3 前置条件单独准备
- 2.4 被调用的函数放在后面
- 关于注释
- 3.1 什么情况下需要注释,什么情况下不需要
- 3.2 好的注释
- 3.3 坏的注释
写出来的代码,只要逻辑对了,就能运行,这使得一部分人对于代码质量不是很看重,代码读起来犹如天书。但总有一些追求卓越的人,精益求精,不只是代码性能高,可阅读性,可维护性同样很强。看他们的代码,就像是在欣赏一件艺术品,美轮美奂,字里行间都透着一股严谨专业的技术范。
你也想写出那种漂亮的代码么,本文总结了业内普遍认可的代码编写原则,规范,遵照这些原则和规范,你也可以写出专业级的代码。
1. 命名要有意义
无意义的命名,会影响代码的阅读,让人看得云里雾里
1.1 见其名,而知其意
好的变量名字,让人一眼便能大概猜的出它的作用,而糟糕的变量名字,虽然编写代码时省去了起名字的时间,但后续维护代码却不得不付出更多的时间。
stu_c = 10 |
stu_count 很容易被理解,它存储记录学生的数量,而stu_c就无法起到同样的效果,更不用说那些为了省事而用单个字母做变量的情况。
方法或函数的名称,尽量加上动词,比如下面的例子
def get_stu_name(): |
类的名称,则使用名词短语,比如BankAccount, Book, HttpCode
1.2 避免误导
如果你在命名时,想通过名称传递一些信息,那么在使用过程中,一定要始终如一的坚持
stu_list = [('小明', 14), ('小刚', 15)] |
最初命名变量时,你期望通过名称传达一个信息,这个变量是列表类型,可是在随后的使用中,你不小心将其变为了字典,那么这就存在了误导,其他人可能继续将其当做一个列表来使用。
命名误导开发人员,更多的发生在函数和方法的命名上,比如我的另一篇讨论函数命名的文章为你的函数起一个好的名字 所提到的jieba模块的一个函数load_userdict, 这个函数名称让人一看到就以为需要传入一个字典,但实际情况却不是这样,你需要传入一个字符串或者一个file-like 类型的对象。
1.3 避免太短,或是太长
变量名称果断,根本起不到任何提示和辅助回忆的作用,而如果变量名称太长了,又会占用太多屏幕空间,同时也不利于阅读。使用驼峰命名,还是蛇形命名,这个要看个人喜好和一种编程语言默认的习惯。
1.4 避免在名称后面加数字
这种命名方式还是挺普遍的
count_1 = 20 |
count_1与count_2 都是用来计数的,可是一个1,一个2,这能表达什么呢?get_stu_info已经明确的表明函数是用来获取学生信息的,那么这个get_stu_info_2又是来做什么的呢?通常,如果两个函数功能很类似,但是参数不同,我会这样命名
def get_stu_info_by_id(id): |
2. 函数或方法要安全,简洁
2.1 单个函数代码行数不应过多
一个函数有100行代码,听起来只有100行,并不多,但一整个屏幕已经无法显示全部的函数代码了。当一个函数里的代码过多时,或者是功能不够单一,或者是一些本应该抽象出来单独作为一个函数的逻辑片段没有被抽象,总之,你写了一个非常糟糕的代码。
函数尽量短小,最好不要超过50行。
2.2 功能要单一,只做一件事情
功能越是单一,就越是安全,因为你修改一处代码时,需要额外考虑的条件就越少,你只需要关注这一小块逻辑即可。许多个功能,累加到一起,就实现了一个更大的功能,而这个实现更大功能的函数里,并没有太多的代码,都是对实现小功能函数的调用,这个时候,你就能感受得到函数功能单一的的魅力了。相比于所有代码都挤在一个函数里,你可以通过这些短小的函数更清楚的知道函数实现的步骤和细节,阅读代码的人会更有体会。
2.3 前置条件单独准备
其实这一点和函数功能要单一是相同的,只是从另一个角度进行了阐释。当你用unittest 模块对代码进行测试时,测试用例的编写需要定义一个类继承TestCase, 如果需要为测试准备一些条件,那么这些逻辑应当写在setUp方法中。这就是我所讲的前置条件单独准备。
一个函数,承诺只做一件事情,实现一个单一的功能,假如函数的执行需要一些条件,那么,这个条件最好不要在函数内部运行时准备,而是明确的放在函数外部准备。因为通常情况下,调用你函数的人不会事先完整的阅读你的代码,它并不清楚这个函数还做了一些额外的准备操作或者善后操作,这种情况下就容易引发意外,或者在函数使用出现问题时不知从何处着手解决问题。
2.4 被调用的函数放在后面
有时候,一个模块写了很多函数,几百行代码放在一起,尽快你遵守规则进行命名,阅读代码也是一件不易的事情。如果函数之间存在调用关系,那么就把他们放在一起,而且被调用的函数放在后面,这样,你在阅读代码时,很容易找到他们。
3. 关于注释
3.1 什么情况下需要注释,什么情况下不需要
- 如果函数很短小,且函数名称已经非常准确的表明了函数的功能作用,那么就没必要添加注释
- 如果函数里代码行数很多,即便函数名称遵守了规则,也应当添加注释
- 如果函数的参数很多,那么应当添加注释,至少得把这些参数解释清楚,否则调用函数的人不知道如何传递参数
- 关键的业务逻辑,或者特殊的逻辑分支,需要添加注释
3.2 好的注释
- 特殊的逻辑,要解释清楚来龙去脉,这种事情很常见,产品经理突然找到你,某种情况下,我们这么处理,对于这种特殊情况,请务必做好注释,否则将来维护代码的人根本不知道你这样写的缘由,也就根本不敢修改
- 如果有需要完善的地方,请写好 todo
- 多写为什么,少写是什么,是什么至少可以通过阅读代码来了解,但是为什么就是一个对阅读代码的人完全没有头绪的事情。
- 解释你的架构设计,并不是每个人都已经达到架构师的水平,如果你的代码设计的很精妙,用了许多高级语法和技术,请适当的做一些解释的工作,写代码是为了给别人看的,不是用来show的,代码里的奇技淫巧向来不受待见。
3.3 坏的注释
没有所谓坏的注释,只要不是错误的注释,在我看来都是好注释,即便注释写的驴唇不对马嘴,相比于完全没有注释的代码,我喜欢前者。