http导读
本节内容围绕http相关的知识展开,不论是web后端开发,还是爬虫开发,都需要对http相关的知识有一定的了解和掌握。
浏览器发出一次http请求,直至收到响应后显示内容,这个中间过程究竟都经历了什么?
如何用socket直接发送http请求,服务端响应的本质有是什么。
一段url里的中文,为什么都是乱码?怎么样使用python下载图片?
这些问题,都可以在这一小节中获得答案。
一次http请求之旅系列—浏览器是如何工作的
不论是web开发还是爬虫开发,都应该懂一些基础的http协议知识,倘若想成为万里挑一的高手,那么,就必须精通http协议及其周边技术,如果你想对这方面有所专研,推荐一本书籍《http权威指南》。
本文尝试用清晰简明的语言,以一次http请求为切入点,讲解http协议的基本知识,你若能耐心读完,必定会大幅度提升你对浏览器,网站,以及爬虫的认知与理解。
鉴于本文内容较长,微信阅读不方便,我将分几次推送内容。
1. 浏览器是如何工作的?
浏览器是一个软件,它是如何工作的?
1.1 普通人眼里的浏览器
在普通人的眼里,浏览器就是用来上网的,它的工作模式如下图所示
1.2 初级程序员眼里的浏览器
在初级程序员眼里,浏览器的工作模式变得复杂了一些,他们已经知道一些基础的web知识
在初级程序员眼里,对于浏览器的理解,已经抛弃掉打开浏览器,输入网址等与底层技术无关的动作,将自己的注意里集中在浏览器器发送请求,服务器返回请求,浏览器处理请求这三个动作上
1.3 高级程序员眼里的浏览器
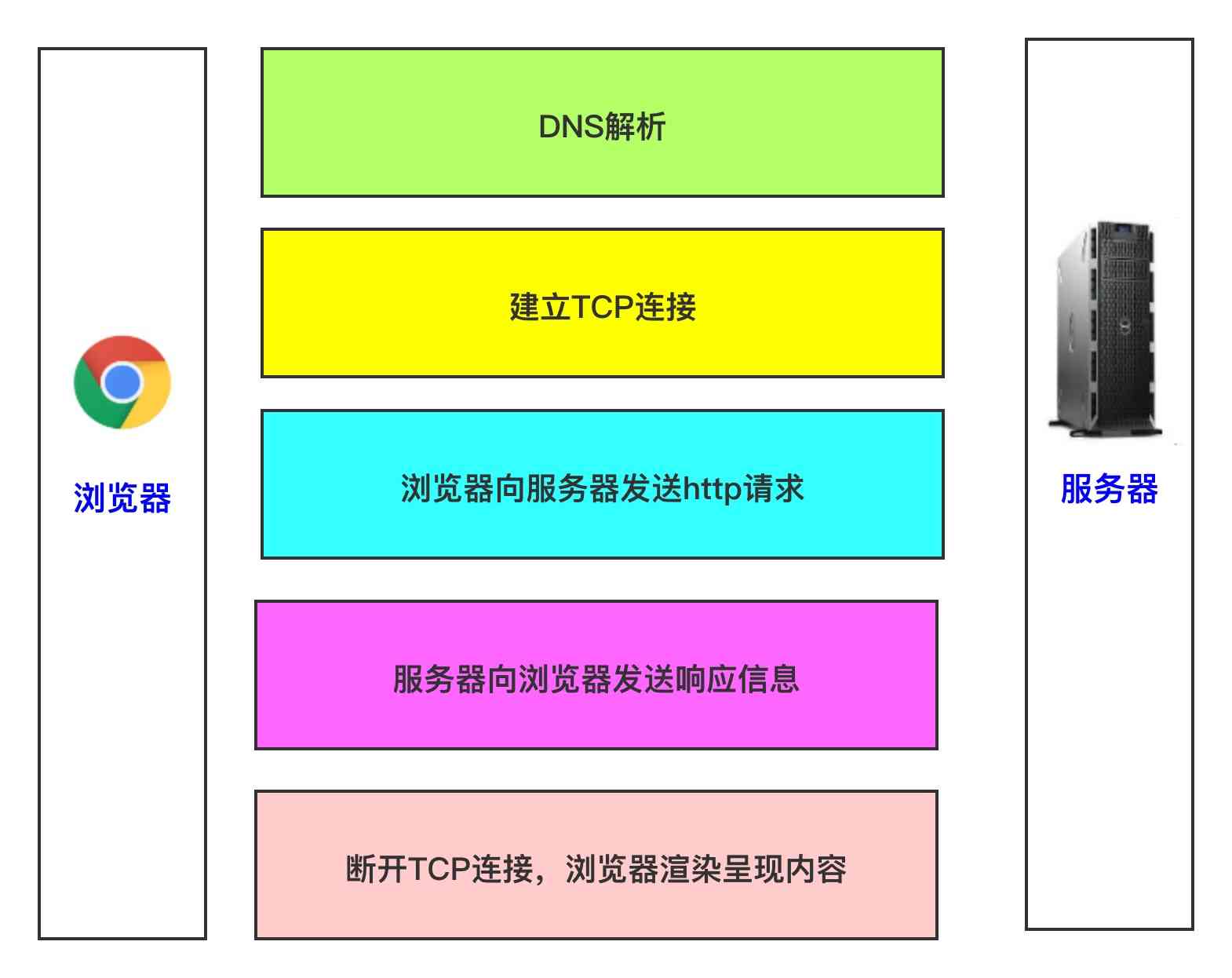
在本文后续的论述中,使用图3代表本图。
在高级程序员眼里,对浏览器行为了解的更为透彻,对技术的关注更倾向于底层实现,对上图中间的5个部分,本文将一一作出讲解:
- DNS解析
- 建立TCP连接
- 浏览器向服务器发送http请求
- 服务器向浏览器发送响应信息
- 断开TCP连接,浏览器渲染呈现内容
一次http请求之旅系列—建立TCP连接
1. 建立TCP连接
1.1 TCP 服务端与客户端
web服务的本质,是一个TCP server, 浏览器则是一个TCP client。图3中黄色的部分就是建立TCP连接,只有先建立连接,浏览器才能通过这个连接发送http请求。你可能注意到,我直接越过了DNS解析,直接讲解第2部分内容,这是因为必须先理解TCP连接,才能理解DNS解析。
下面的代码是一份TCP 服务端的示例
import socket |
客户端代码的编写也十分容易
import socket |
建立TCP的过程,有一个重要的概念—3次握手。这个问题经常在面试中被用来考察应聘者对于socket的了解程度。
1.2 什么是TCP3次握手
客户端与服务端在建立正是的连接之前,要互相试探着询问对方是否愿意与自己建立连接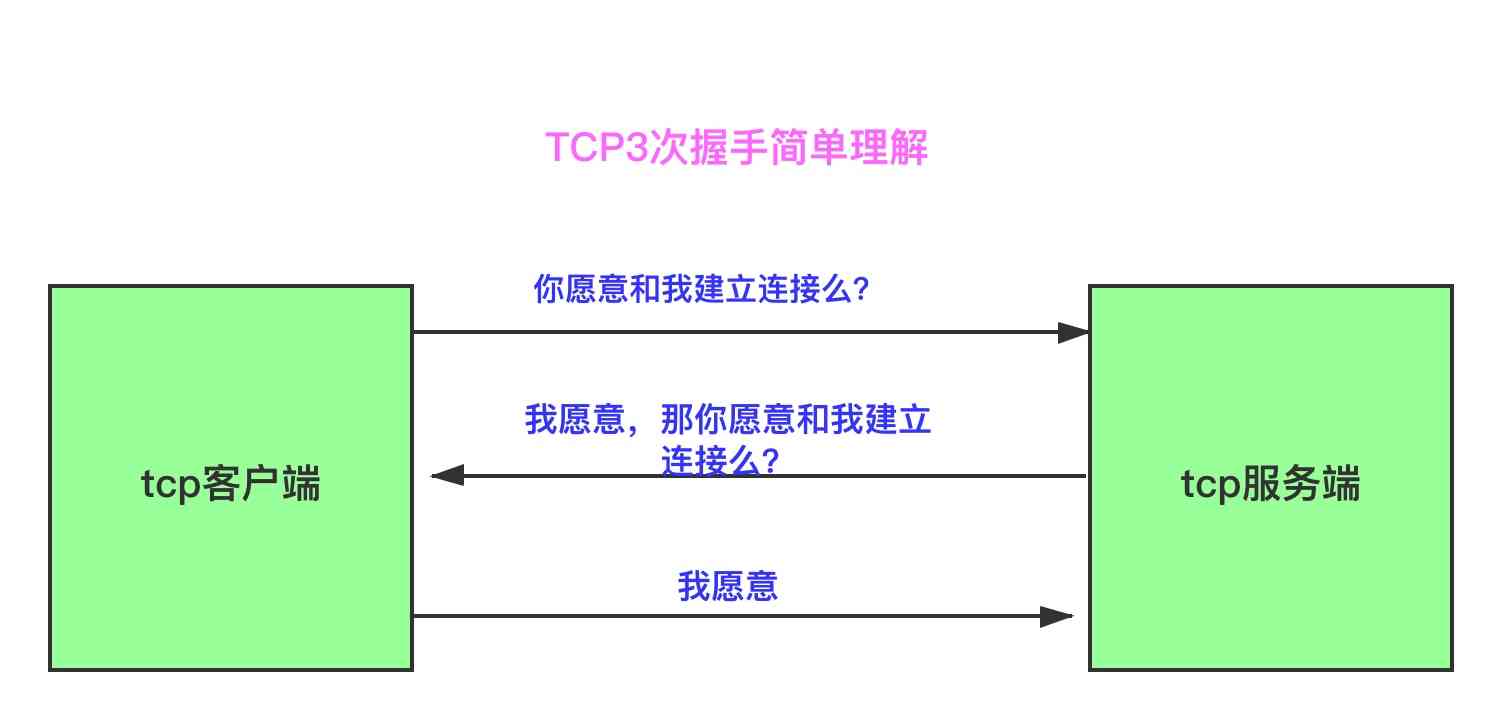
上面所画的,阐述的是一种十分简单的理解,只是对功能进行了描述,并没有从技术层面上解答何为tcp3次握手,而想要从技术层面上做出解释,则必须先了解TCP头结构
下图是TCP头结构,客户端与服务端发送数据时,必须准守TCP/IP协议,按照指定的格式发送数据,TCP的头结构携带了许多关键信息,比如源端口号与目的端口号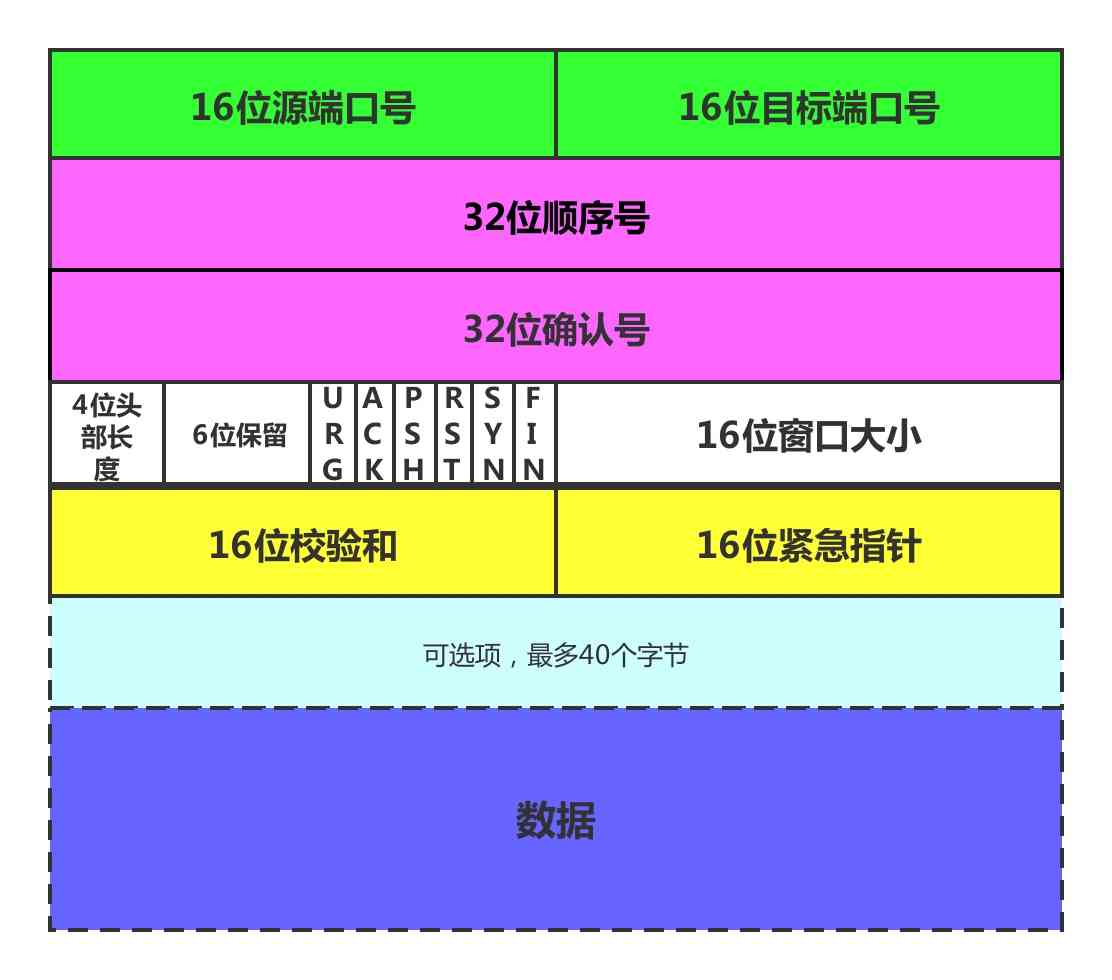
注意看上图中,中间白色的那一块区域,找到SYN和ACK,这两个各站1个bit位,是3次握手的关键:
- 客户端向服务端发送syn包,所谓的syn包,是指SYN为1
- 服务端收到syn包以后,发送syn+ack包,这时,SYN和ACK都是1
- 客户端向服务端发送ACK包,ACK标识位是1
这便是TCP建立连接时的3次握手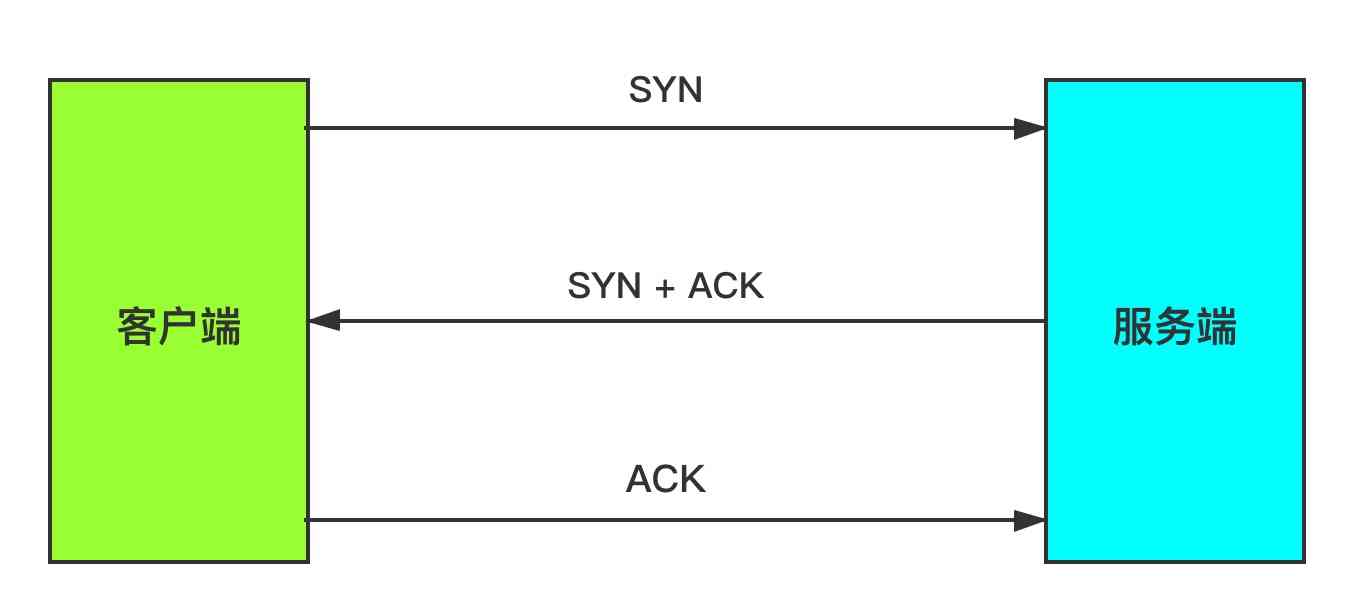
1.3 为什么是3次握手,而不是2次
看上去,似乎两次握手就可以了,服务端在收到SYN包后回复ACK确认可以建立连接不就行了么,为何非要让服务端也发SYN,客户端再回ACK呢?
之所要求3次握手,是为了防止已经失效的SYN包意外的到达服务端,造成双方的不一致。
考虑这种情况,客户端向服务端发出了SYN包S1, 可好巧不巧的是,S1由于网络阻塞或其他原因在网络中滞留,毕竟从客户端到服务器隔着十万八千里呢,中间是好多个交换机路由器等网络设备,网络也会堵车。发生网络堵车后,客户端以为S1丢包了,于是又发出一个SYN包S2,S2顺利的到达服务端,如果握手只需要两次,那么服务端回一个ACK就建立好连接了。
可别忘了网络中还有一个S1,S1并不知道客户端又发出了S2,它恪尽职守的穿越重重障碍,在S2之后到达服务端,如果这个时候S2所建立的连接还存在,那么服务端会无视S1,但如果S2所建立的连接已经断开了呢?服务端会以以为S1是一个新的连接请求,服务端回ACK,建立连接,客户端收到ACK后,就有点懵逼了,它完全不知道是怎么回事,也不知道该如何处理这个突然到达的ACK包,这样一来,两边都会浪费很多资源。
2次握手建立连接,会发生上述的意外,但是3次握手就不会,服务端与客户端都要发送SYN包并回复对方ACK包,只有这样才会建立连接,服务端在回复ACK的时候,顺带着把SYN设置为1,这样就免去了单独发送SYN包的步骤,3次握手即可建立连接。
一次http请求之旅系列第3讲—DNS解析
你可能遇到过,或者你身边的朋友曾经遇到过这样诡异的事情,电脑无法上网,但是QQ是可以登录的。这种情况,是由于DNS解析异常导致的。
浏览器在底层本质上是一个socket客户端,当你想要在浏览器里打开百度首页时,你输入网址www.baidu.com并点击回车后,浏览器需要与百度服务器建立TCP连接,这就需要知道百度服务器的IP 和 端口号, 端口号默认是80, 但是IP是多少呢, 所谓DNS解析,就是根据网站域名找到IP。
1. 域名与IP
一个网站,可能会有多个域名,多个IP,在终端里执行下面的命令
ping coolpython.net |
在我的电脑里得到下面的结果
PING coolpython.net (101.201.37.248): 56 data bytes |
在浏览器里直接输入ip,就打开了我的个人技术博客,我这只是一个小网站,只用一个域名就可以了,不需通过DNS做负载均衡,因此只需要一个ip就可以了。在网站域名coolpython.net 和 服务器IP 101.201.37.248之间存在一个映射关系,这个关系保存在DNS服务器中。我们人类的记忆更适合记录那些看起来有点意义的东西,记录一个域名要要比记录一个IP地址要容易的多。
2. DNS解析过程
当我们在浏览器里输入一个网站域名后,会现在本地查找这个域名所对应的IP,在hosts文件中,如果有这个域名的记录,那么就完成查找,这部分是系统缓存的数据。
如果在hosts文件中找不到,则向本地DNS服务器发起请求,请求解析这个域名的ip,所谓本地DNS服务器是指你的网络服务提供商,联通,电信。如果他们可以找到映射关系就会把对应的IP返回给你。
如果本地DNS服务器找不到,则向根域名服务器继续发请求,根域名服务器还是找不到,就继续向上,向A顶级域名服务器发送请求,直至找到为止。
那么会不会出现最终也找不到的情况呢? 如果找不到,可能是由于这个域名有问题了,服务商已经停止了对它的解析。平时所遇到的无法上网但是可以登录QQ的情况是由于你电脑里DNS服务器所配置的IP出问题了,百度一个可用的DNS服务器IP替换一下就好,QQ走的UDP,不是TCP,因此不受DNS解析的影响。
requests快速入门
requests是一个对开发人员非常友好的http库,它接口简单,灵活易用,平日里写爬虫程序,我便直接使用requests发送http请求,本文带你快速了解这个库的基本用法: 发送get请求, 发送post请求, 下载图片, 获取json数据等
1. 发送get请求
import requests |
status_code是Response状态码,200表示服务器成功响应,res.text是返回的html源码
2. 下载图片
from PIL import Image |
content是Response数据的2进制形式,text是字符串形式,使用Image的show方法可以直接显示图片
3. 获取json数据
import requests |
如果返回的数据是json格式的,那么可以直接使用json方法来获取数据,这样就不需要使用json.loads方法将res.text转换为python类型数据了
4. 发送post请求
import requests |
httpbin.org 这个网站可以测试http请求和响应的各种信息,可以作为练习使用
5. SSL验证
requests可以想web浏览器那样为https请求验证SSL证书
import requests |
如果网站的SSL证书有问题,请求将会失败
6. 查看http响应的header信息
import requests |
url相关技术
在涉及到http的编程过程中,很容易遇到url编码问题和url解析的需求, url编码和url解码总是成对出现,对于url的解析,可以使用urllib.parse模块的urlparse函数
1. url编码与解码
在浏览器里打开下面这个网址
https://baike.baidu.com/item/URL%E7%BC%96%E7%A0%81/3703727?fr=aladdin |
你在浏览器网址输入栏里看到的url是这样的
中文的部分在浏览器里可以正常显示,但是如果你把它复制出来粘贴到文本编辑器中,中文部分就会变成 %E7%BC%96%E7%A0%81
在URL里,任何特殊的字符,即不是ASCII的字符,包括汉字都会被编码,比如空格,在URL里用%20来代替。
在网络编程中,经常会使用到url编码
from urllib.parse import quote, unquote |
程序输出结果
https://baike.baidu.com/item/URL编码/3703727?fr=aladdin |
2. url解析
对url解析使用urllib.parse模块的urlparse函数,解析十分方便
from urllib.parse import urlparse |
程序输出结果
ParseResult(scheme='https', netloc='www.baidu.com', path='/s', params='', query='wd=url%20%E7%BC%96%E7%A0%81', fragment='') |
python用socket发送http请求
平时我们使用浏览器浏览web资源,写爬虫的时候,我们会使用封装好的库,比如requests,或者使用爬虫框架。工欲善其事必先利其器,顶层封装好的东西,是为了我们使用着方便,节省开发时间,尽管各种http库功能强大,但学习底层的技术仍然有着实践意义,只有了解底层,才能真正理解顶层的封装和设计,遇到那些艰难的问题时,才会有思路,有方案。
1. 用socket发送http请求
浏览器也好,爬虫框架也罢,在最底层,都是在使用socket发送http请求,然后接收服务端返回的数据,浏览器会对返回的数据进行渲染,最终呈现在我们眼前,爬虫框架相比于浏览器,只是少了一个渲染的过程。
用socket发送http请求,首先要建立一个TCP socket,然后连接到服务端socket,http请求的3次握手,本质上是TCP socket建立连接的3次握手。连接建立好了以后,就要发送数据了,这里的数据,可不是随意发送的,而是要遵照http协议,下面的代码,演示了socket发送http请求的过程
import socket |
代码非常简单,不做过多解释,我们重点要了解的是http协议,request_url的内容是
GET /article-types/6/ HTTP/1.1 |
请求的消息头,每一行都有各自的作用,在消息头和消息体之间,有两次换行,由于我们发送的是GET请求,没有消息体,因此两个换行后就结束了。
这3行,每一行都至关重要。
第一行的内容,包含了三个重要信息
- GET 指明本次请求所使用的method,这是一次GET请求
- /article-types/6/ 指明了要请求的资源地址
- HTTP/1.1 指明http协议的版本,更早以前是1.0,现在大家都在用1.1
第二行的内容,指明了host,一台服务器上,也许不只是部署了一个web服务,而是多个,他们都是80端口,url = ‘www.zhangdongshengtech.com‘ 只是告诉socket去哪里建立连接,这仅仅是个域名而已,程序根据域名找到IP地址,如果服务端部署多个服务,为了服务端区分一个请求是指向哪个服务,客户端需要在请求头中指明host,服务端会根据这个host来做请求的转发,这就是常说的nginx反向代理。
第三行,定义了Connection的值是close,如果不定义,默认是keep-alive, 如果是keep-alive,那么服务端在返回数据后不会断开连接,而是允许客户端继续使用这个连接发送请求,我故意设置成close,目的就是让服务端主动断开,这样,当程序在使用while循环时,接收完所有的数据后,sock.recv(1024) 返回的就是None,这样,就可以停止程序了。如果是keep-alive,无法通过连接断开来判断数据是否已经全部接收,那么就只能通过返回数据的消息头来获取数据的长度,进而决定本次请求返回的数据到哪里结束。
2. 返回的消息体
程序输出了服务端返回的数据,由于数据量很大,我们只截取消息头的部分进行讲解,消息体只是网页源码而已,没什么可说的。
HTTP/1.1 200 OK |
返回的数据中,消息头和消息体之间,也是两个换行。
第一行,HTTP/1.1 200 OK 指明了http协议的版本,已经本次请求返回的状态码,200表示成功响应,比较常见的还有404,500,302,这些状态码的含义,你可以自己百度一下。
第二行开始的消息头内容中,比较重要的是Content-Length,它的值是29492,这表明,消息体的长度是29492,如果Connection的值是keep-alive,客户端就得根据这个值来读取消息体。
请求的消息体和服务端响应的消息体中,除了第一行外,其他的长的很像字典形式的key-value对,叫首部,本文只涉及到个别几个首部,其他首部及其含义,你可以自行百度。
3. 从消息头解析出content_length
增加一点难度,从消息头里获取content_length,在获取返回数据时,当消息体的长度满足要求时,停止获取数据,并关闭连接
import socket |
使用socket写一个最简单的web服务器
http协议是基于TCP实现的, 我们所熟知的nginx, tomcat, apache等服务器,本质上就是一个tcp server, 只要你对http协议有少许的了解,就可以自己实现一个简单的web服务器,当然,它只能是一个你用来验证http协议和提升自己编程能力的小玩意。
1. TCP server
直接上代码,然后再解释代码
import socket |
消息头
head的定义完全遵守http协议,Content-Length 是可以不用设置的,因为Connection被设置成了close,如果是keep-alive,那么就必须设置Content-Length
消息体
消息体就是一段html,关于html可以参考文章爬虫数据分析之html
2. 浏览器访问
启动程序后,就可以在浏览器里输入url http://localhost:8080/ 得到的页面内容很简单,只有一个hello world
此时,只要url前面是http://localhost:8080/ ,后面不管跟什么path,得到的结果都是相同的,这是因为我们的server太简单了,没有根据path返回对应的内容,为了让你更进一步的了解http请求时都发生了什么,接下来,我要修改这个server
import socket |
升级后的server,可以对http://localhost:8080/name 和 http://localhost:8080/ 做出正确的响应,访问其他的资源则会返回404
本篇实现的服务器,是最最简单的服务器,但它和那些普遍使用的服务器,诸如nginx,tomcat在原理上是一致的,不同的是他们可以实现多进程,多线程,使用的epoll模型。
你用flask写一个web程序,最终部署的时候,用的可能是nginx,中间件用uwsgi,结构更加复杂,但本质上就是TCP server