python第三方库导读
python有多少第三方库? 这个问题恐怕没有一个准确的答案,人们只知道几乎所有你想要事项的功能,早已经有人写好了python库,你所需要做的,只是尽快找到它并学会如何使用它。python的发展得益于开源社区的开源精神,人们热衷于将自己的成果展示在互联网上并希望能够帮助到别人,你可以在github和pypi上找到大量python开源库。
本专题致力于向你介绍那些有趣的第三方python库,他们解决了不同的问题,或许某一天,你有机会用到他们,学习他们的开源代码也是一个可以让你快速进步的方法。
如何学习使用第三方模块
得益于python强大的开源社区,我们在使用python开发项目时,可以几乎可以做到全程拿来主义。需要什么,就百度好了,总会有人已经实现了你需要的功能模块,你所需要做的仅仅是使用pip命令安装他们。
虽然你不必重复造轮子,但理解掌握别人已经早好的轮子有时候也并非易事。本文介绍3种学习第三方库的方法
- 搜索第三方库文档
- 阅读源码例子, 测试脚本
- 编译第三方模块说明文档
1. 搜索第三方库文档
这是最快速,最有效的学习第三方库的方法,别无其他,假设你想学习requests这个http库,那么最好的办法是用百度搜索这个库的文档,关键词: python reqeusts。百度会给你提供大量的教程连接
运气好,可以直接找到第三方库的官方网址,或者找到国内已经翻译好的教程。选择一份你喜欢的,讲解详细,示例多的教程,慢慢学习吧!
2. 阅读源码例子, 测试脚本
有些第三方库的作者并没有提供官方的文档,或者还没有人将英文的文档翻译成中文,或者文档讲解不细致,总之,使用搜索引擎找不到合适的文档,那么这个时候,你就要考虑从源码里寻找可用的资源,例如源码中的代码示例或者测试脚本。
事实上存在这样的情况,作者认为自己所开发的库或者模块比较简单,无需提供详细的使用文档,但他会在源码里写一些示例代码,还有些作者自己会写测试脚本以验证自己的代码是健壮的,通过示例代码和测试脚本,你仍然可以快速学习第三方库的使用方法。
很多作者都会把开源项目放在github上,因此想要找源码,github最合适不过,以web框架bottle为例,在git仓库里有一个test文件夹,这里就保留了大量作者用以测试框架的代码,你完全可以通过阅读这些测试代码来学习该框架
以excel操作库xlrd为例,源码里不仅有tests文件夹,还有一个examples文件夹,提供了示例代码。
3.编译项目使用说明文档
有些作者会在源码里提供项目使用说明文档,以xlwt为例,项目文档存放在docs中,将源码下载到本地,并进入到docs目录中,你会看到很多以.rst结尾的文件,rst于Python类似Javadoc与Java,我们可以将其转为html后用浏览器打开。
在转换之前,你需要先安装sphinx
pip3 install sphinx |
编译说明文档有两种方式
方式1, 进入到源码,执行命令
sudo sphinx-build -b html docs build |
docs就是保存rst文件的文件夹,上面的命令会生成一个build文件,在这个文件夹里有一个index.html文件,用浏览器打开这个文件,就可以看到帮助说明文档
方式2, 进入docs文件夹,执行命令
make html |
该命令会在docs文件夹下生成一个_build目录,和方法1里生成的build一样,保存了一些html文件,使用浏览器打开index.html,就可以查看说明文档了。
python文字转语音模块
pyttsx3是一个文字转语音的python库,更多信息参考官方网站
值得称道的是这个库是跨平台的,在mac os, windows都可以使用,安装方式如下
pip3 install pyttsx3 |
使用该模块非常简单
import pyttsx3 |
我在mac上实验该模块,python版本是3.6,不论中文还是英文都可以正常发出声音
pyinstrument
pyinstrument是一款python性能分析器,它通过记录程序执行过程中的堆栈记录来帮你找出程序最耗时的代码。pyinstrument每1毫秒中断一次程序,并在那一点记录整个堆栈,单个函数的执行时长会在函数执行结束后被记录。当你的python程序性能需要优化时,可以考虑使用pyinstrument来定位程序慢在哪里。
使用pip进行安装
pip install pyinstrument |
1. 如何使用pyinstrument
在终端里运行 pyinstrument 命令, 得到如下结果
kwsy@zhangdongshengdeMacBook-Air:~/kwsy/coolpython$ pyinstrument |
根据提示, 我们应该用pyinstrument命令来运行一个脚本
pyinstrument [options] scriptfile [arg] |
我新建一个名为demo.py的脚本,内容较为简单
import requests |
在这个脚本里,我想要详细记录函数test_api的执行过程,那么我需要在函数执行之前创建Profiler对象并启动它,在函数执行结束之后结束它,最后使用output_text方法输出调用栈的记录,由于我们在脚本里直接调用了output_text输出,因此可以直接使用python命令来运行程序
python3 demo.py |
执行结果为
200 |
如果想获得更好的观察效果,或者对输出结果持久化保存,那么可以使用pyinstrument命令并配合适当的参数
pyinstrument --outfile=2.html -r html --hide=EXPR demo.py |
这几个参数分别指定了输出文件和输出文件的类型,hide参数设置将调用过程中内置库的调用信息隐藏,最终得到的是一个html文件,打开后的效果如下
2. 配合flask使用
pyinstrument开发人员给了一份配合flask使用的示例代码
from flask import Flask, g, make_response, request |
before_request 会在视图处理请求前执行,after_request会在请求得到处理后返回结果前执行,如果请求的参数里包含了profile参数,表示需要记录整个调用栈的信息,当请求得到响应后,会调用output_html方法得到一个html页面,并将其返回,作者给的这个例子非常使用,但只适用于get请求,在浏览器里发出get请求,加入profile参数,就可以在浏览器里得到整个调用过程中调用堆栈的信息。
3. pyinstrument与profile(cProfile)有什么不同
按照作者的解释,Pyinstrument是一个统计分析器,而profile是跟踪分析器,Pyinstrument每隔1ms记录一次堆栈的情况,它不会跟踪程序进行的每个函数调用, 这样一来,系统开销就会小很多,以Django模板渲染进行测试,得到的结果如下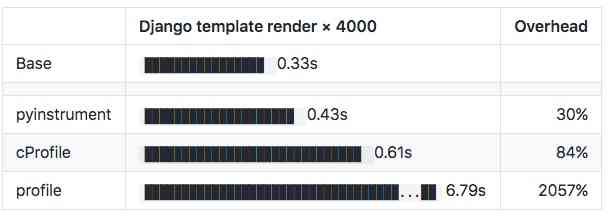
你可以看到,在使用pyinstrument时,仅仅比基础速度慢了30%, 而cProfile则慢了84%,cProfile 这类跟踪分析器由于大量调用探查器,可能会扭曲结果。
另一个不同在于,标准的python探查器获取了函数的执行时长,profile或者cProfile会根据每个函数的执行时长进行排序并展示,但是这些函数为什么会被调用,被谁调用等问题则不能给出令人满意的答案, 但pyinstrument会记录整个堆栈,因此可以完美的展示调用关系,并且会默认隐藏内置木块和标准库的调用信息。
watchdog—在python中创建看门狗,监控文件系统变化
看门狗是一款小软件,可以监控文件和目录是否发生变化,watchdog就是一款可以监控文件系统变化的第三方模块,当被监视的区域发生文件或目录的创建,修改,或者删除时,就可以引发特定的事件,我们只需要编写针对这些事件的函数即可处理这些变化。
1. 安装和导入
使用pip来安装
pip install watchdog |
导入所需要的模块
import time |
2. 创建事件处理对象
在创建事件处理对象时,有很多有用的参数需要进行设置
watch_patterns = "*.py;*.txt" # 监控文件的模式 |
- watch_patterns 设置监控文件的模式,如果你想监控所有文件,那么设置成”*” 即可,我所设置的模式只会监控以.py 和 .txt结尾的文件
- ignore_patterns 设置忽略的文件模式,我这里没有忽略任何文件
- ignore_directories 设置为True表示忽略文件夹的变化
- case_sensitive 设置大小写是否敏感,如果设置为True,那么修改文件名称时,如果只是大小写发生变化,那么则不会被监控
3. 处理事件
def on_created(event): |
一共有四种事件需要处理,对应的,编写4个函数
4. 创建观察者
最终,我们需要创建一个观察者,来负责启动监控任务
watch_path = "/Users/kwsy/data/test" # 监控目录 |
- watch_path 设置监控的目录
- go_recursively 设置为True表示监控子文件夹
一个观察者可以多次使用schedule方法来监控文件系统,这样,我们可以一次监控多个区域,每个区域使用不同的监控策略。
现在,在所监控的目录下执行新建文件的操作,就会被这段程序所监控到,并使用on_created函数做相应的处理。
防止rm误删除
1. trash-cli
rm -rf |
上面这个命令,恐怕是这个世界上最危险的命令,在每一次程序员删库跑路的事件中都扮演着关键角色。在日常工作中,一不留神,就可能因一时疏忽而误删除了关键文件导致服务器出现故障或是服务不可用。由于linux系统没有回收站功能,这导致使用rm删除的文件很难恢复。
本文给大家介绍的,是一个实现了回收站功能的python库,使用它,你可以放心的执行rm命令而不必担心误删除的数据无法恢复,使用pip进行安装
pip install trash-cli |
安装结束后,你可以使用which trash 来查看工具的安装目录,在我的机器上,安装目录是/opt/conda/bin , 使用ll /opt/conda/bin/trash* 命令可以查看到所有相关命令
/opt/conda/bin/trash # 删除文件, 同trash-put |
你可以使用trash命令代替rm命令,更好的方法是设置rm命令的别名,修改.bashrc文件,增加下面这行
alias rm="trash" |
设置以后,记得执行source .bashrc 使配置生效,现在,你可以放心的使用rm命令了,当你想恢复某个文件时,执行trash-list 列出回收站中的文件,使用trash-restore 恢复你想要恢复的文件。
2. trash-cli 实现原理
2.1 被删除的文件去哪了
你一定好奇,那些被删除的文件去哪了,默认情况下,这些文件都被放在了 $HOME/.local/share/Trash 目录下,这个目录下有两个文件夹,分别是files 和info, files目录下存放的就是被删除的文件,info目录下存放的是被删除文件的信息,包括被删除前所在目录和被删除时间,格式如下
[Trash Info] |
每一个被删除的文件或文件夹,都会有一个与之相对应的trashinfo文件,记录着被删除文件的关键信息。当使用trash-restore恢复文件时,就是根据这些信息将文件move到指定位置。
2.2 回收站的目录是否可设置
默认是$HOME/.local/share/Trash ,但可以进行修改,这一点,源码里说的很清楚
class HomeTrashCan: |
如果你希望更改回收站的目录,那么可以通过设置XDG_DATA_HOME 环境变量来实现。