多线程导读
如果你只是使用多线程完成一些简单的操作,那么python提供的threading模块可以非常轻松的帮你解决,你甚至会产生一种错觉,多线程也不过如此。
但你应该有个心理准备,任何技术,一旦专研进去,就是一片全新的天地,很多人都知道多线程在修改同一个变量时需要进行互斥,但你知道这背后的原因么?互斥需要加锁,那么python提供的Lock锁和RLock锁有什么区别呢?线程同步有几种方法,他们分别是什么?
在多线程专题中,这些问题将一一解答。
python多线程基础概念
python的多线程由threading模块提供多线程的实现,python多线程的基础概念,包括GIL锁,如何线程的ID,如何启动线程,如何传入参数,如何创建后台线程, 如何使用join连接子线程并等待子线程全部结束。
- 多线程基础概念
- GIL锁
- 线程ID
- 启动多线程
- 继承threading.Thread
- 传入参数
- 后台线程
- join
1. GIL锁
python的多线程,并不是真正的多线程,因为有Global Interpreter Lock这个bug一般的全局锁存在,这使得同一时刻,只能有一个线程在执行。
需要注意的是,GIL锁并不是python语言的特性,它是实现CPython时引入的概念。一门语言的代码,可以由多种编译器来编译,比如C++的代码,你可以用GCC 来编译,也可以用Visual C++,同理,一段python代码也可以在不同的执行环境来执行,比如CPython,PyPy,JPython,这其中,JPython就没有GIL锁,由于CPython是默认的执行环境,因此,给大家造成了误会,以为python这门语言很蛋疼的弄了一个GIL锁。
由于有全局锁的存在,所以,python很难有效的利用多核,但也不是一点用处都没有了,在IO密集型的任务里,还是有用武之地的,比如你写一个多线程的爬虫,一个线程的请求发出去以后,需要等待服务器返回数据,其他的线程就可以继续执行了,充分利用网络IO。
2. 线程ID
有很多文章告诉你如何获取线程的id,方法就是threading.currentThread().ident ,但这是不对的,ident只是线程的标识,而非线程id,正确的做法是使用ctypes库获取,方法如下
import threading |
上述代码要在linux环境下才能执行, 当然,你也可以将线程标识用于区分线程。
3. 启动多线程
import threading |
你所看到的,是一个非常简单的启动多线程的方法
- 使用threading.Thread创建一个线程,target参数指定的是线程要执行的任务
- 使用start()方法启动一个线程
- 观察打印内容可以发现,整个进程要等到子线程t结束后才会结束
仰赖于python语言的简洁性,启动一个多线程非常的简单,程序输出结果
0 |
4. 继承threading.Thread
除了第3小节所展示的方法以外,还可以通过继承threading.Thread来创建一个线程
import threading |
采用这种方法时,必须实现run方法
5. 传入参数
修改my_print方法
def my_print(count): |
通过args向线程传入参数
t = threading.Thread(target=my_print, args=(5, )) |
args需要传入一个元组,因此,尽管只有一个参数,也要写一个逗号
6. 后台线程
import threading |
使用setDaemon方法将线程设置为后台线程,这意味着,主线程就不会等待它结束,执行程序,输出结果为
0 |
线程启动后刚刚输出一个0,主线程就已经结束了,由于子线程是后台线程,因此输出内容不会在控制台上显示,如果你不喜欢主线程等待子线程运行的结果,那么就可以将子线程设置成后台线程
7. join
之前的示例代码中,启动线程后,立刻执行主线程里的代码,在实际应用中,通常,会使用join方法,等待子线程执行结束
import threading |
三个子线程都是用join()方法,只有他们都执行结束以后才会执行print(‘主线程’), 等待的时间是可以设置的,比如将上面的程序改为t.join(0.1),那么主线程会每个程序都等待0.1秒钟的时间,0.3秒钟以后,主线程就不再继续等了,开始执行自己的代码,如果不设置时间就表示一直等待,直到所有子线程结束
python threading.local 线程隔离
threading.local() 返回的是一个特殊的对象,它的状态是线程隔离的,每个线程的对value赋值,其实是在对不同的值进行赋值,你应该知道,python的对象里,属性值保存在字典中,显然,mylocal里保存了多份字典,区分他们的正是线程ID”
1. 输出结果是多少
先看一段代码
import threading |
这段代码的最终输出结果是多少呢?如果你有一定的多线程编程经验,你应该会回答说结果不确定,因为mylocal.value的最终值是不确定的,10个线程对它进行写操作,只有最后那个执行的线程才会生效,实际的过程比这还要复杂
对内存中一个变量进行修改,可总结为三个步骤
- 将变量读取到寄存器中
- 在寄存器中修改
- 写回内存
哪个线程最后执行这第3步,哪个线程的执行是生效的, 你能理解到这一层次,已经非常好了,但是,这不是上面问题的答案
2. 线程隔离
实际执行上述代码的结果是0,threading.local() 返回的是一个特殊的对象,它的状态是线程隔离的,每个线程的对value赋值,其实是在对不同的值进行赋值,你应该知道,python的对象里,属性值保存在字典中,显然,mylocal里保存了多份字典,区分他们的正是线程ID
web框架flask,基于Werkzeug实现,而Werkzeug 自己封装了werkzeug.local.Local ,其效果和threading.local 基本一致,但也有一些不同,正是由于使用了这样的技术,所以App Context 对象和 Request Context 对象是请求间隔离的,也就是说,在多线程环境下,每个request对象都会准确的找到自己的信息
为什么python多线程同时写一个数据会不安全
本文使用python语言讲解为什么多线程在不加锁的情况下同时修改一个变量是不安全的, 启动5个线程,每个线程都会对变量a执行100000次加1操作, 最后print(a)时,最直观的猜想,a的值是500000,然而实际情况却并不是这样,下面这段代码,将像你展示这种情形
import threading |
启动5个线程,每个线程都会对变量a执行100000次加1操作, 最后print(a)时,最直观的猜想,a的值是500000,然而实际情况却并不是这样。
a最终的值会小于500000,这究竟是怎么一回事呢。
要想解释这个现象,就必须弄清楚,对变量加1这个操作是怎样完成的,在程序里,你只需要写a = a + 1 就可以完成一次对变量的加1操作,但在计算机内部,真实的加1过程却经历了很多
下图是一个线程对变量执行加1的过程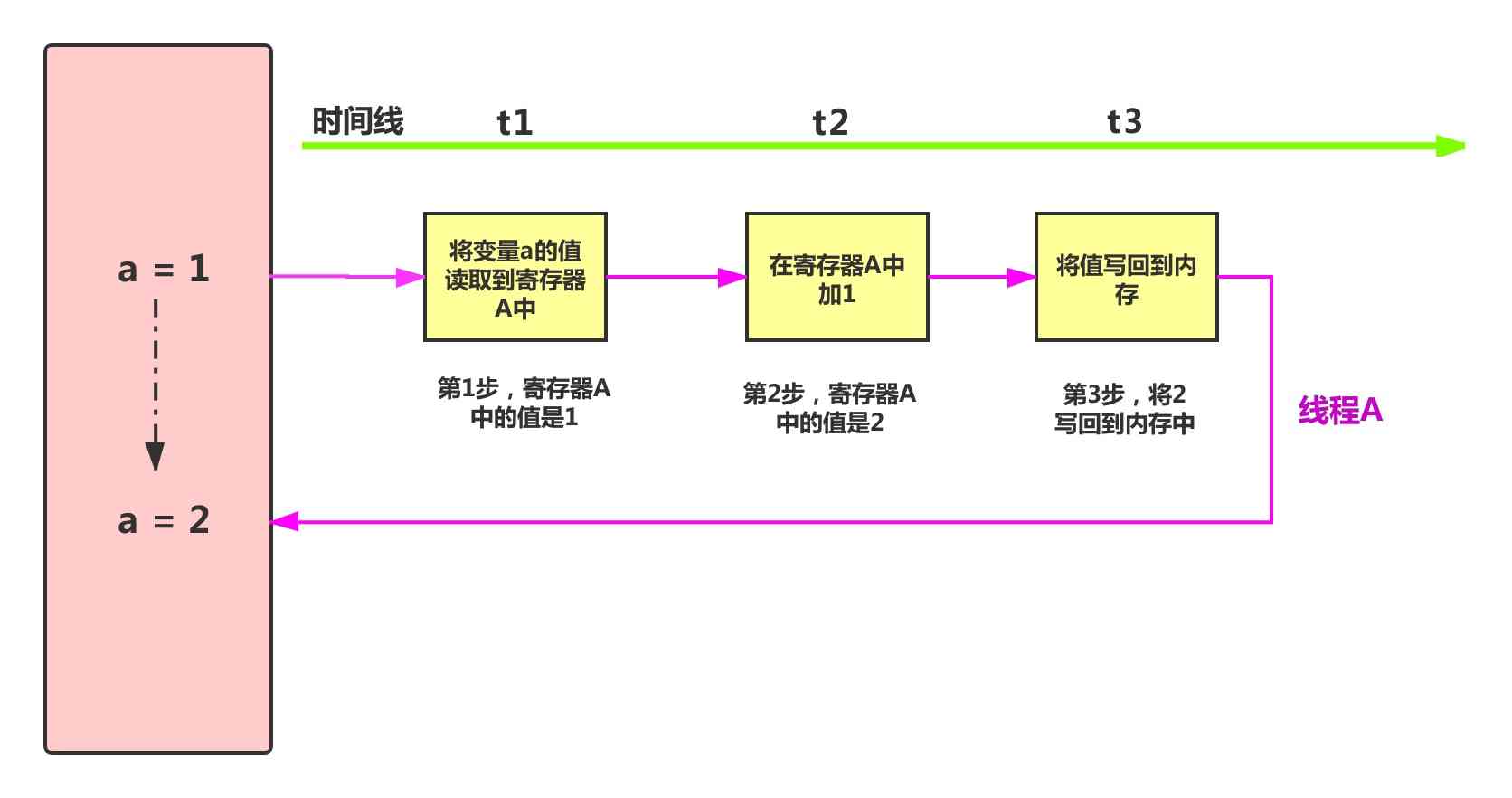
对变量执行加1操作,分为3个步骤
- 将变量的值读取到寄存器中
- 在寄存器中进行加1操作
- 将寄存器中的值写回到内存中
有了这个认识以后,再来看两个线程同时对变量a进行加1操作的过程
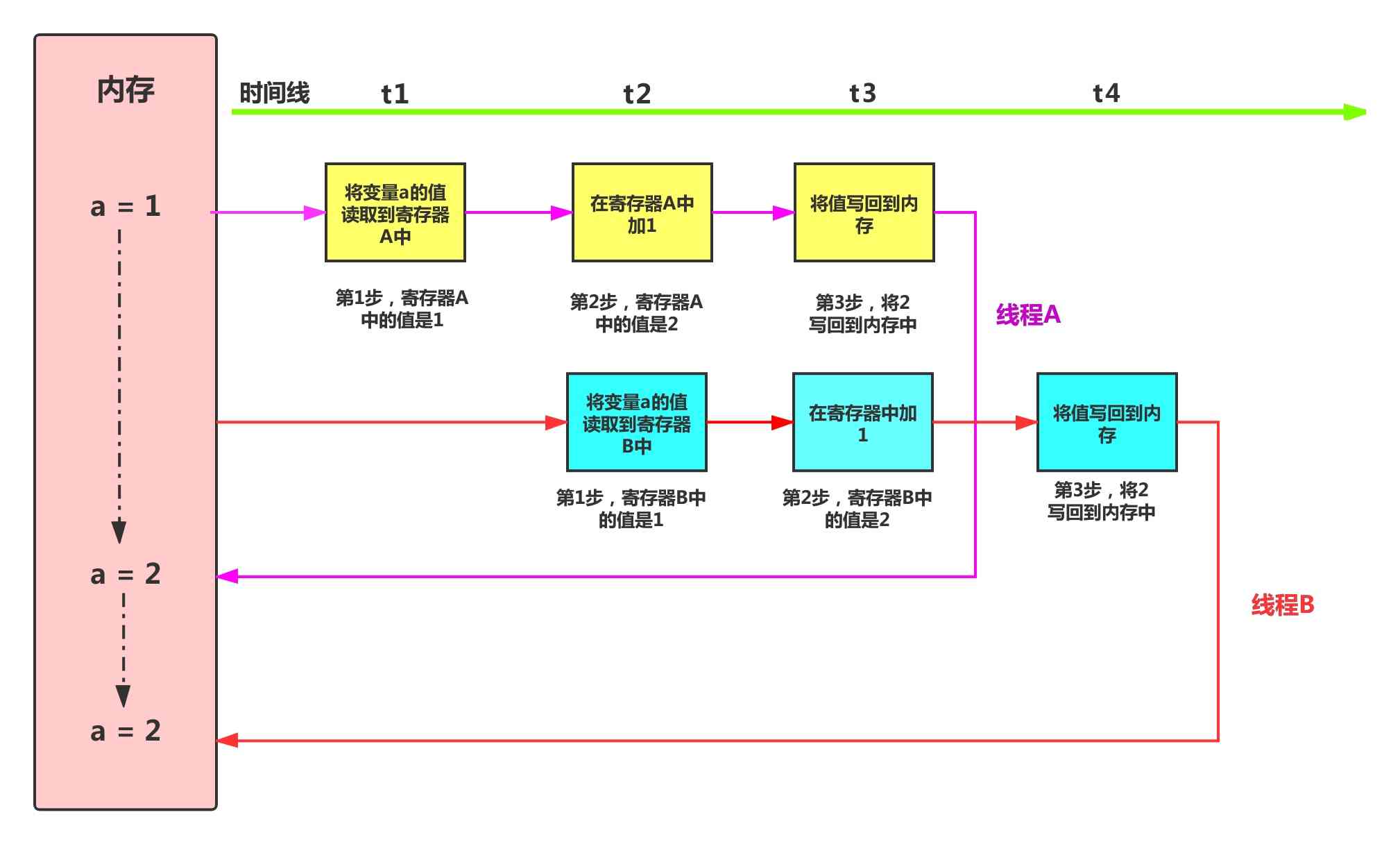
线程A在t1时刻启动,线程B在t2时刻启动,问题就出在t2这个时刻,仔细观察示意图,你会注意到几点事实
- 内存里,a的值是1
- 线程A已经在寄存器里将1变为2
- 线程B将内存中的1读取到寄存器B中
这就是事情的全部真相,t2时刻,线程B在线程A还没有完成一次加1操作时,将内存中的数据读取到寄存器中。
t3时刻,线程A将2写回到内存中,而这一刻,线程B在寄存器中进行加1操作,寄存器中的值是2
t4时刻,线程B将2写回到内存,两个线程都执行了加1操作,可内存中变量a的值仍然是2。
通过两个线程执行加1操作过程的分析,相信你已经明白了,问题的根本在于对于我们所写的一行代码,计算机在执行时有很多操作,而这些操作之间会互相影响,这导致了线程不安全,那么怎么才能消除这种影响呢,咱们下回分解。
python多线程—线程锁
在使用python进行多线程编程时, 为了防止多线程同时修改同一个变量, 使用threading.Lock()对关键操作加锁, 进程有自己独立的内存单元,而线程则共享创建他们的进程的内存单元,多线程在运行时,如果要对同一个资源进行使用,那么就会面临资源共享的问题,处理不当,会对数据造成破坏
1. 资源共享
进程有自己独立的内存单元,而线程则共享创建他们的进程的内存单元,多线程在运行时,如果要对同一个资源进行使用,那么就会面临资源共享的问题,处理不当,会对数据造成破坏, 在上一篇文章中,你已经见识到了多进程同时修改变量所引发的数据冲突问题。
为了避免这种情况的发生,我们需要在对共享资源进行修改时加锁,同一个时刻,只能有一个线程获得这把锁,然后对数据进行操作,其他的线程只能等待。这样,就可以避免多个线程同时修改一份数据。
2. 线程锁
你可以使用threading.Lock()对关键操作加锁, 我修改上一篇所使用的代码
import threading |
仅仅添加了两行代码,进行加锁和释放锁的操作,就可以获得锁期望的结果了,最终a的值是500000
你也可以使用with语句来简化代码,避免忘记释放锁
def worker(): |
python多线程Lock和RLock的区别
Lock和RLock的区别
- 两种锁的不同
- 1.1 定义
- 1.3 可重入锁
- 怎么会多次请求锁呢?
1. 两种锁的不同
1.1 定义
为了确保对共享资源的访问,python提供了两种锁,一个是上一篇提到的Lock,还有一个就是RLock,他们的区别在于:
Lock是可用的最低级别的同步指令,一个线程只能请求一次,而RLock是可以被一个线程请求多次的同步指令
当Lock处于锁定状态时,不被特定的线程所拥有,而RLock使用了“拥有的线程”和“递归等级”的概念,因此处于锁定状态时,可以被线程拥有
1.2 死锁
Lock在下面的情形下会发生死锁
Lock.acquire()
Lock.acquire()
Lock.release()
Lock.release()连续两次acquire请求,会导致死锁,因为第一次获得锁之后还没有释放时,第二次acquire请求紧接着就到来,可是acquire会让程序阻塞,无法执行release(),这就导致锁永远无法释放,死锁是非常危险非常严重的问题
1.3 可重入锁
RLock就不存在1.2中所提到的死锁问题
RLock.acquire() |
不过要保证有多少次acquire(),就有多少次release()
2. 怎么会多次请求锁呢?
最初接触到Lock和RLock这两者之间的不同之处时,感到十分困惑。RLock的优势在于,在同一个线程里可以多次申请锁,而Lock则不能,必须在释放之后才能再次申请,那么,这样做也没问题啊,不会出现第一次申请后,在释放前又申请的可能啊,在编写代码的时候,完全可以认为的控制这种情况的发生。
然而事实并非如此,我现在假设一种情形,使得死锁的发生不可避免
import threading |
上面的例子中,h()和g()中都用了Lock,在多线程环境下,他们可以做到相安无事,但是,程序的结构总是处于变化中,尤其是那些庞大的系统,一个小小的变化可能牵一发而动全身,假设发生了下面的变化
import threading |
在h()函数中,获得锁以后要执行g(),那么此时,程序就会发生死锁,在大的项目里,情况会比这更加复杂,你很难通过眼前的几行代码发现这种死锁的情况,因为很可能发生死锁的地方是在很深层次的调用过程中,因此,使用RLock是非常安全的选择.
执行上面的代码,程序不会输出任何信息,也永远不会结束,因为已经发生了死锁,将注释的Lock替换成RLock,程序立马可以执行
python多线程线程同步—Condition
生产者与消费者模型是最为常见的多线程编程问题, 本文使用python语言利用Condition线程同步技术来解决生产者与消费者问题, 在这个过程中, 你将学习了解到多线程如何进行同步
python多线程线程同步—Condition
- 生产者-消费者模型
- 线程同步
- 条件变量–Condition
- 3.1 wait
- 3.2 notify
- 示例代码
- 4.1 生产者都调用了wait方法
- 4.2 notify
- 4.3 wait 和 release
1. 生产者-消费者模型
生产者与消费者模型是最为常见的多线程编程问题,它可以简要的总结为以下内容:
- 有一个商品池,存储商品
- 有若干个生产者,当商品池中商品的数量小于某个值时开始生产商品并放入到商品池中
- 有若干个消费者,当商品池中商品的数量大于某个值时开始消费商品
商品池中的商品数量是动态变化的,学习生产者和消费者模型,你需要关心以下几个问题:
- 生产者和消费者都会操作商品池,那么它必须是线程安全的,在多线程下访问共享资源,不出现数据不一致或者污染数据
- 生产者和消费者之间如何协调工作
2. 线程同步
线程同步的意思不是几个线程同时进行某个操作,而是指线程之间协同步调,这个“同”字是协同的意思,而不是同时的意思,在本例的生产者与消费者模型中,我希望能做到这样的同步(你也可以设计你的同步方式,如何同步,不是固定死的套路):
- 一个生产者生产商品后,能够进入到等待状态,由其他生产者或者消费者进行生产或消费操作
- 一个消费者消费商品后,能够进入到等待状态,由其他消费者或者生产者进行消费或生产操作
3. 条件变量–Condition
Condition被称为条件变量,除了提供与Lock类似的acquire和release方法外,还提供了wait和notify方法,如果你已经对锁有一定了解,那么,你对acquire和release肯定不陌生了,我重点介绍一下wait和notify方法
3.1 wait
调用这个方法,会释放掉底层的锁,那么看来,此前,一定是得到锁了。没错,使用condition的第一步就是调用acquire方法,这一步已经获得了锁。我们可以认为condition对象维护了一个锁,如果你不指定这个锁,默认是RLock锁,同时还维护了一个waiting池,调用wait方法后,waitting池会记录这个线程,同时,这个线程也进入到了阻塞状态,直到超时或者别的线程唤醒它。
当这些线程被唤醒以后,会重新试图去获得锁
3.2 notify
这个方法会唤醒处于waiting状态的线程,能唤醒多少个呢?这取决于传入的参数,如果不传,默认唤醒其中一个,如3.1中所说,被唤醒的这个线程会再次acquire锁,得到锁以后继续执行
4. 示例代码
代码并非我原创,而是从网上抄录下来的一篇,我重点来解释代码
import threading |
4.1 生产者都调用了wait方法
在这个例子中,我把products的初始值设置为12,这样,两个生产者启动以后,都会调用wait方法,我这样设计的目的是想告诉你,wait的作用是释放掉底层的锁,只有这样,消费者线程启动以后,再调用acquire时才会成功获得锁,千万不要误以为wait会一直把持锁,实际上它释放了锁,然后等待被唤醒
4.2 notify
因为一次只有一个线程能够得到这把锁,其他线程都处于waiting状态,因此不论是生产者也好,还是消费者也罢,在自己完成生产或消费活动后,都要调用notify方法,唤醒其他线程,假设A线程调用了notify,唤醒了B线程,那么B线程会立刻获得锁么?答案是不会
因为此时,锁依然掌握在A线程手中,要注意,notify方法并不会归还锁,它只是唤醒其他线程,要等到A线程release时才会真正的释放掉锁,这时,B线程才会得到锁,如果A线程调用的是nofity(3),那么同时有3个线程被唤醒,这3个线程会争抢锁,最终也只有一个会获得锁
4.3 wait 和 release
我期初对这两个东西是比较困惑的,他们都释放了底层的锁,那么调用完了wait,是不是就可以不用再调用release了呢?答案是不可以
wait的确是释放了底层锁,这个作用和release是一样的,但是,调用wait后,线程就阻塞在那里了,一直等到被唤醒才会继续执行之后的代码,可以被唤醒就意味着要去获得锁,如果得不到锁,会继续尝试获得锁,如果得到锁,就必须用release来释放掉锁
严格的讲,一个acquire必须对应一个release,他们必须成对出现,切记
python多线程同步—信号量 Semaphore
python多线程编程中的Semaphore, 它内部维护了一个计数器,每一次acquire操作都会让计数器减1,每一次release操作都会让计数器加1,当计数器为0时,任何线程的acquire操作都不会成功,Semaphore确保对资源的访问有一个上限, 这样,就可以控制并发量
python多线程同步—信号量 Semaphore
- 内容回顾
- 1.1 Lock
- 1.2 RLock
- 1.3 Condition
- 信号量
- 示例代码
1. 内容回顾
在多线程的系列里,我已经讲解了Lock,RLock,Condition,在讲解信号量之前,不妨先做一个简单的内容回顾
1.1 Lock
对一个变量进行加1操作,远比我们以为的要复杂,从内存到寄存器,执行加1,写回内存,这就引申出了多线程情况下对共享资源的访问的问题。有些操作是线程安全的,有些操作是线程不安全的,对于那些线程不安全的操作,我们必须为这个操作加上一把锁,来确保同一个时刻,只能有一个线程进行操作,就像加1的操作,要等到彻底执行完,也就是写回到内存后才允许其他线程进行操作
1.2 RLock
RLock的作用和Lock一样,不同的地方在于,它可以被一个线程多次请求,只要你保证每一个acquire对应一个release就可以保证线程不会发生死锁,它比Lock更加安全,尤其当程序复杂时,推荐你使用RLock
1.3 Condition
Condition,也称作条件变量,它也可以实现多线程对共享资源的互斥访问,相比于Lock,RLock,它更加灵活,其灵活之处在于它提供了wait操作和notify操作。
假设这样一个场景,你有2个生产者线程,10个消费者线程,当商品数量大于10个的时候,生产者不再生产,商品数量为0时,不再消费,如果是用RLock来做线程间互斥,当商品数量为0时,按道理说消费者线程是不进行任何消费活动的,但是,这些消费者线程仍然在拼命的尝试来获得锁,得到锁以后,发现商品数量为0,于是再释放掉锁,紧接着去争抢锁。
如果是用Condition来做呢,消费者发现商品数量为0时,可以进行wait操作,此时,线程进入等待状态,再没有被唤醒之前,它是不会去争抢锁的,极端的情况是商品为0时,10个消费者都进入到wait状态,而这时,生产者获得锁,生产了商品,然后进行notify操作,去唤醒一个线程,当然这次唤醒的可能是另一个生产者,不过没关系,总会又一次唤醒的是消费者线程。
condition和Lock,RLock相比较,在生产者和消费者模型中,避免了不必要的对锁的争抢,更加高效的调用线程资源。
2. 信号量
来谈一谈Semaphore,它内部维护了一个计数器,每一次acquire操作都会让计数器减1,每一次release操作都会让计数器加1,当计数器为0时,任何线程的acquire操作都不会成功,Semaphore确保对资源的访问有一个上限, 这样,就可以控制并发量。
如果使用Lock,RLock,那么只能有一个线程获得对资源的访问,但现实中的问题并不总是这样,假设这样一个场景,一个线程安全的操作,同一个时刻可以允许两个线程进行,如果太多了效率会降低,那么Lock,Rlock,包括Condition就不适合这种场景。
我这里举一个不恰当的例子(因为我自己没这么干过,但有助于你理解)。假设你写了一个多线程爬虫,起10个线程去爬页面,10个线程访问过于频繁了,目标网站对你采取反爬措施。但你把线程数量降到2两个就没问题了。那么对于这个场景,你仍然可以启动10个线程,只是向目标网站发送请求的这个操作,你可以用Semaphore来控制,使得同一个时刻只有两个线程在请求页面
3. 示例代码
import threading |
python多线程同步—事件 Event
事件 Event是另一种python多线程同步技术, 本文将使用python语言对这种技术进行讲解, 想象这样一个场景,你启动了多个线程,这些线程都要去访问一个资源,但是,这里有一个小小的问题,即将被访问的资源还没有准备好接受访问,那么此时,多个线程去访问,必然得到不响应,你还得处理这种得不到响应的情况
python多线程同步—事件 Event
- Event
- 1.1 set()
- 1.2 wait()
- 1.3 clear()
- 1.4 is_set()
- 协调线程同步
- 一个更复杂的例子
1. Event
借助Event,可以灵活的协调线程间的操作,它提供了下面几个方法
1.1 set()
将事件内部标识设置为True,Event对象最初创建时,内部标识默认是False
1.2 wait()
当在线程中调用wait时,如果事件内部标识为False,则会阻塞,直到set方法被调用,将内部标识设置为True
1.3 clear()
将内部标识重新设置为False
1.4 is_set()
如果内部标识是True,则返回True,反之,返回False
2. 协调线程同步
想象这样一个场景,你启动了多个线程,这些线程都要去访问一个资源,但是,这里有一个小小的问题,即将被访问的资源还没有准备好接受访问,那么此时,多个线程去访问,必然得到不响应,你还得处理这种得不到响应的情况。
这样的场景下,能否先在主线程里去做试探,确定资源可以访问以后,再让已经启动了的多线程去访问呢?让我们考虑一下如何用Event来处理这样的问题
- 创建一个Event对象,现在,事件内部标识是False
- 启动多线程,线程里调用wait方法,这时,会阻塞
- 主线程去试探,确定资源可访问以后,调用set方法
- 已经调用wait的线程接手到事件信息,访问资源
以下为示例代码
import threading |
3. 一个更复杂的例子
一个线程依次打印1 3 5 ,一个线程依次打印 2 4 6,使用事件做消息同步,使得两个线程启动后,打印出1 2 3 4 5 6, 别看要求很简单,但实现起来却是有难度的,每个线程输出不同的数列,但整体上看却要求有序。
针对这样的线程同步要求,可以创建两个Event对象,两个线程互相触发另一个线程的Event对象
import threading |
python 多线程练习题—四个线程同步打印a b c d
1. 题目描述
有四个线程,每个线程只打印一个字符,这四个字符分别是 a b c d ,现在要求你做到四个线程顺序打印 a b c d ,且每个线程都打印10次
2. 思路分析
假设1 线程只打印a字符,题目要求打印10次,那必然要写一个循环来打印,难点在于,1线程打印一个a之后,不能打印第二个a,因为题目要求的是这四个线程要顺序打印a b c d,这就意味着2 线程接下来要打印b,然后3 线程打印c ,最后4 线程打印d。
这样,第一轮就结束了,接下来,还要打印第二轮。
1线程打印完一个a之后,必须能够通知2线程,并且保证自己不继续打印a,而2线程则必须通知3线程,3线程再通知4号线程,4号线程通知1号线程,周而复始。每个线程在输出前,都必须等待,等待一个通知,通知到了才能打印,不然一股脑的循环打印所有字符,就不能满足四个线程顺序打印a b c d 的要求了
3. 示例代码
有了第二步对题目的分析,我决定使用Event对这四个线程进行同步,创建4个event对象,分别属于这四个线程,在1号线程里,属于自己的那个event对象调用wait方法进入阻塞状态,同时,也传入2号线程所拥有的event,这样,当1号线程完成打印后,可以用这个event对象去告诉2号线程可以打印了
import threading |
使用concurrent.futures 模块提供的线程池进行并发
concurrent.futures 从python 3.2 版本被加入到发行版中,它提供了线程池和进程池,具有管理并行编程任务、处理非确定性的执行流程、进程/线程同步等功能, 它的submit和map方法可以让你快速的实现多线程并发。
使用线程池,你无需关心线程的创建与销毁,结果的收集,使用起来极为方便,下图是对线程池工作原理的解释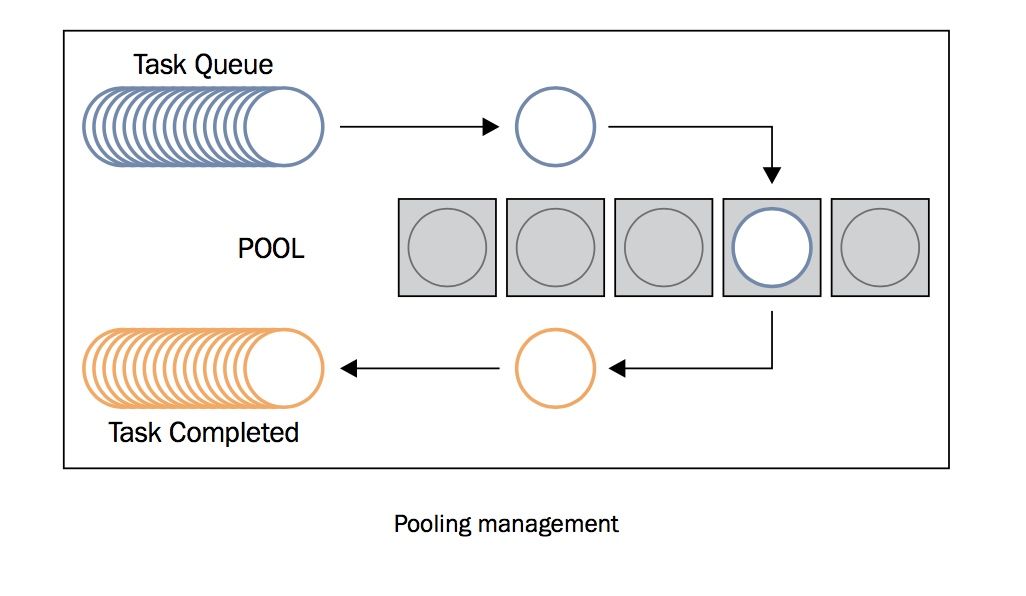
1. 使用submit提交任务到线程池
假设你有1000个url需要进行爬取,这类任务十分适合使用多线程处理。让我们看看使用concurrent.futures 提供的线程池该如何进行并发。
import time |
线程池只是提供了并发的机制,你需要自己完成并发时需要调用的函数,这里指的是crawl, 它完成单次任务,爬取一个url并返回结果。
接下来,第1步创建线程池, max_workers 定义了线程池的大小
with concurrent.futures.ThreadPoolExecutor(max_workers=30) as executor: |
第2步,向线程池提交任务
futures = [executor.submit(crawl, url) for url in urls] |
调用executor 的submit方法,第一个参数是在线程中需要被执行的函数,从第二个参数开始是函数所需要参数。futures 里存储的并不是最终的结果,而是future对象,要等到线程执行函数有了返回值以后才能调用result方法获得返回结果。
第3步,等待返回结果
for future in concurrent.futures.as_completed(futures): |
你不必关系哪个线程完成了一次crawl函数的调用,as_completed方法会帮你识别出已经完成的任务,调用result方法即可获得crawl函数的返回值。
这里要特别强调一点,crawl_result存储的数据与urls 之间是不存在依据索引位置的一一对应关系的,在代码里,我输出了crawl_result前10个元素
[84, 30, 295, 49, 278, 584, 177, 922, 1144, 416, 634, 29, 28, 1026, 294, 277, 176, 583, 1143, 415] |
显然,与urls之间毫无关联关系,urls中的0是最先被提交的,但未必是最先完成的,因此这两个列表的索引是不能最为输入与输出之间的映射关系的。如果想要在他们之间建立某个联系,建议在crawl 函数的返回值中加入输入的参数url , 根据这个url 就能够找到对应的urls中的输入信息。
2. 使用map方法并发执行任务
map 与 submit 的最显著的区别在于,map方法返回的结果是有序的
import time |
map方法会遍历urls,传入crawl 函数进行调用,返回的结果res是一个生成器,其结果是有序的,使用list方法将生成器转为列表,输出前20个元素
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19] |
这与urls的前20个元素是一一对应的。