多进程导读
1. 学习多进程
关于这个问题,你大概了解过一些概念,比如CPU密集型的任务适合使用多进程,IO密集型的任务可以使用多线程。这都只是很笼统的说法,实际上,关于何时使用多进程何时使用多线程,要考虑的因素很多。并发编程本身是一件困难的事情,在没有明确问题关键点,没有找到系统瓶颈前,贸然的使用多进程或者多线程,只会引入新的问题而不是解决问题。
在我工作的大部分时间里,很少用到多进程,这是由工作内容决定的,但学习理解多进程仍然是有必要的,虽然自己工作中用不到,但工作中所使用的其他系统和工具可能是多进程相关的,了解多进程,有助于你了解所使用的工具。
2. 父进程,子进程
当我们提到多进程时,一定是指父进程产生了一些子进程,他们之间有着紧密的联系。父进程如何产生子进程,本教程只讲解fork这一种方式,这是linux系统的实现方式,redis将内存中的数据保存到硬盘时会fork出一个子进程来进行这个操作。
我们所熟知的nginx,实际处理请求的也是子进程,子进程的数量建议设置为CPU的核数。部署python web系统时所使用uwsgi所采用的也是多进程。
3. 并行的关键
不论是多进程还是多线程,并行的关键在于如何分配任务。一定是存在大量的任务单个进程无法满足要求,我们才使用多进程进行处理,期望每个进程处理任务的一部分。既然每个子进程只处理任务的一部分,那么如何分配这些任务就成为了问题的关键。
任务的分配,最直接,最简单的办法是使用队列,python的multiprcessing模块提供了Queue,它是线程安全和进程安全的。
python多进程之multiprocessing
- python多进程之multiprocessing
- Process 类
- 继承 Process 类
- 进程池
- map 与 map_async
multiprocessing与threading有着相似的API,是一个用于产生进程的包。使用这个模块,可以让你轻松的创建出多进程程序。
1. Process 类
创建一个Process类的实例,然后调用它的start方法就可以创建出一个子进程,下面看一个简单的示例
import time |
程序输出结果
主进程pid: 19544 |
- os.getpid() 可以获取当前进程的pid
- os.getppid() 可以获取当前进程的父进程pid
一旦提到多进程,必然是一个主进程(父进程)产生出至少一个子进程,至于主进程如何产生出子进程,在不同的系统下有着不同的实现,下面是python官方文档对于多进程启动方式的介绍:
spawn
父进程启动一个新的Python解释器进程。子进程只会继承那些运行进程对象的 run() 方法所需的资源。特别是父进程中非必须的文件描述符和句柄不会被继承。相对于使用 fork 或者 forkserver,使用这个方法启动进程相当慢。
可在Unix和Windows上使用。 Windows上的默认设置。
fork
父进程使用 os.fork() 来产生 Python 解释器分叉。子进程在开始时实际上与父进程相同。父进程的所有资源都由子进程继承。请注意,安全分叉多线程进程是棘手的。
只存在于Unix。Unix中的默认值。
forkserver
程序启动并选择* forkserver * 启动方法时,将启动服务器进程。从那时起,每当需要一个新进程时,父进程就会连接到服务器并请求它分叉一个新进程。分叉服务器进程是单线程的,因此使用 os.fork() 是安全的。没有不必要的资源被继承。
可在Unix平台上使用,支持通过Unix管道传递文件描述符
在创建Process实例时,需要指明子进程需要执行的函数以及需要传入的参数,args的类型是tuple,即便只有一个参数,也要在后面写一个逗号。
只有执行了start方法后,才正式的创建出子进程。
2. 继承 Process 类
在第一小节中,创建子进程时使用的是函数,除了这种方法外,还可以使用类,创建一个类并继承Process,这个类必须实现run方法。
import time |
3. 进程池
进程池内部维护若干个进程,当需要时可以去进程池中获取一个进程,如果进程池中没有可用的进程,程序进入等待状态直到有可用的进程为止。进程池有两种方法,apply_async 和 apply, apply_async是异步的,apply是同步的,一般我们使用异步方法。
已知列表中有10个整数
lst = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] |
现在要求你计算他们的平方,为了加快计算速度,我决定使用多进程,这样操作仅仅是为了向你展示如何使用进程池进行编程。
from multiprocessing import Pool |
程序输出结果
<class 'multiprocessing.pool.ApplyResult'> |
很多人误以为列表results里存储的数据类型是int,但其实是ApplyResult,必须通过get方法才能获得真正的结果。apply(单个任务同步)与apply_async之间的区别我们不必去深究,因为python官方建议废弃apply而使用apply_async,所以,我们只需要了解apply_async就可以了。
在上面的示例中,我启动了拥有4个进程的进程池,当我们启动子进程进行计算时,主进程并没有被阻塞,也就是说主进程也在执行,因此我在代码里加了pool.join()这行代码,它的作用是等待进程池里所有的进程执行结束然后再继续执行主进程里的代码,如果没有这行代码,进程池里的进程还没有运行结束呢,可能主进程就已经结束了。
4. map 与 map_async
map是多个任务同步,map_async是多个任务异步,使用起来差别不大,与apply_async相比,只是改变了编程的方式,其本质是一样的,都是利用多进程并行运算,先来看map版本的并行运算
from multiprocessing import Pool |
程序输出结果
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100] |
再来看map_async版本
from multiprocessing import Pool |
python fork子进程
- python fork子进程
- 初识fork
- 第一个简单示例
- 父子内存关系—写时复制
- 收尸
fork是个好动西,它通过系统调用能够创建出一个与原来进程一模一样的进程,子进程可以执行和父进程一样的代码,通过逻辑控制,也可以让父进程和子进程执行完全不同的代码块。如果你只是会使用multiprocessing模块进行编程,那么并不能说明你真的理解多进程,因为你并不清楚多进程是如何创建的,创建出的子进程与父进程之间的关系是怎样的,也不会明白同一个变量在父进程和子进程都进行修改时会发生什么,知其然,更要知其所以然。
1. 初识fork
创建子进程的过程非常简单
pid = os.fork() |
返回值有三种
- pid < 0 表示创建失败
- pid = 0 此时,处在子进程中
- pid > 0 此时,处在父进程中 pid 的值就是刚刚创建出来的子进程的pid
2. 第一个简单示例
下面看一段简单的代码:
import os |
如果fork函数执行成功,那么从if pid1 < 0 这行代码开始的代码,父进程和子进程都会执行,此时,他们已经是两个完全不相干的进程了。程序输出结果是
主进程 70522 |
3. 父子内存关系—写时复制
对于fork,有一点必须搞清楚,那就是原来父进程里的那些变量和子进程里的变量是什么关系。一种普遍的存在误区的理解是子进程完全拷贝了父进程的数据段、栈和堆上的内容,但实际情况是linux引入了写时拷贝技术,子进程的页表项只想了与父进程相同的物理内存页,这样只拷贝父进程的页表项就可以了,这些页面被标记为只读,如果父子进程都不去修改内存内容,大家相安无事,一旦父子进程中的某一个尝试修改,就会引发缺页异常。此时,内核会尝试为该页面创建一个新的物理页面,并将内容真实的复制到物理页面中,这样,父子页面就各自拥有了各自的物理内存,看下面这段代码:
import os |
程序运行结果
我是主进程 72544 |
在父进程中,我创建了一个TestFork对象,子进程里去修改age的值,然后输出tf.age的值和tf对象的内存地址。子进程各自对tf对象的age属性进行了修改,因此输出的age值是不同的,但是请注意,子进程中tf对象的内存地址和父进程里的是相同的,这是因为程序只是修改了age属性,引发age属性的写时复制,但变量tf仍然指向之前的对象,因此不会引发写时复制,tf的内存地址不会变化。
4. 收尸
如果父进程还存在,而子进程退出了,那么子进程会变成一个僵尸进程,父进程必须为他收尸。如果父进程先结束了,而子进程还没有结束,此时,子进程的父进程就变成了init进程,由它来负责为子进程退出后收尸。
收尸有两种方法,一个是wait,一个是os.waitpid,wait是阻塞的,而os.waitpid可以设置为非阻塞的,本篇重点讲解waitpid。
waitpid函数定义为 def waitpid(pid, options),第一个参数取值有以下几种情况:
pid > 0 等待进程ID为pid的子进程,此时是精确打击
pid = 0 等待与调用进程同一个进程组的任意子进程
pid = -1 等待任意子进程,此时和wait等价
pid < -1 等待进程组ID与pid 绝对值相等的所有子进程
options 是以下几个标志位的组合
- os.WNOHANG 如果子进程没有发生变化,则立刻返回,不会阻塞
- os.WUNTRACED 除了关心终止进程的信息,也关心因信号而停止的子进程信息
- os.WCONTINUED 除了关心终止进程的信息,也关心因受到信号而恢复执行的子进程信息
函数的返回值有两个,分别为pid 和 status:
- pid = 0 表示子进程没有发生变化,status不需要理会
- pid = -1 表示waitpid调用失败,此时要关心status的值,status 为 ECHLD,表示没有发现有子进程需要等待,status 为EINTR,表示函数被信号中断
- pid >0 pid是发生变化的子进程的pid,具体子进程何种状态,因为什么退出,需要根据status来判断,如果子进程是正常退出,status就是0;如果子进程是被信号杀死的,status记录的就是终止的信号;如果子进程被停止,或者恢复执行,status记录对应的值,这里要重点说明一下,假设你是用SIGSTOP信号停止了子进程的运行,这个status的值可不是SIGSTOP所对应的常量值,具体是多少,取决于系统,mac下的和linux下的值是不一样的,那怎么根据status的值来判断是停止还是恢复亦或是被信号杀死呢,还好,系统提供了跨平台的判断方法,具体看下面的例子
#coding=utf-8 |
实验步骤如下:
- 程序启动后,父进程创建一个子进程,然后开始进行waitpid操作,子进程则每隔3秒做一次输出。
- 执行kill -17 + 子进程的PID,子进程会停止打印,同时父进程会提示子进程没有退出,只是停止工作
- 一段时间后,再执行kill -19 +子进程PID,子进程被唤醒,继续打印,而父进程也会提示子进程恢复了运行,
强调一点,我刚才讲述的是在mac环境下,mac和linux环境下的信号所对应的常量值是不一样的,执行kill -l,可以查看信号与常量值之间的关系,如果你是linux环境下实验,发送停止信号时应该是kill -19,发送恢复信号时,应该是kill -18
进程绑定CPU
本文所讲述内容仅适用于linux环境
1. CPU亲和性
CPU亲和性是指进程在某个给定的CPU上长时间运行,尽可能少的迁移到其他处理器的倾向性。linux内核的进程调度器天生就具有这样的特性,它尽可能保证一个进程不在处理器之间频繁的迁移,频繁的迁移意味着会增加CPU缓存miss的概率,增加从主存到CPU缓存的复制时间。
2.6版本linux内核新增了一个机制,它允许开发人员可以编程实现硬CPU亲和性,即程序可以显示的指定进程在哪个CPU上执行。
2. CPU亲和性应用场景
- 有大量计算
- 系统对时间敏感,对性能要求高
最常见的例子就是nginx,在配置nginx子进程的数量时,一般设置成CPU的核心数,同时通过设置worker_cpu_affinity,将不同的子进程绑定到不同的CPU核上,来增强nginx的响应能力。
如果你的服务器只有一个核,那么是否绑定也就无所谓了。
3. python程序如何绑定CPU
Linux 内核 API 提供了一些方法,让用户可以修改位掩码或查看当前的位掩码:
- sched_set_affinity() (用来修改位掩码)
- sched_get_affinity() (用来查看当前的位掩码)
python开发人员不需要使用这么底层的API,第三方库psutil就可以完成这些操作
import psutil |
进程,线程,协程概念
1. 先来对比进程和线程
| 可以拥有自己的独立资源 | 切换消耗 | 是资源分配单位 | 是执行单元 | |
|---|---|---|---|---|
| 进程 | 可以 | 消耗大 | 是 | 否 |
| 线程 | 不可以 | 消耗小 | 否 | 是 |
进程是资源容器,我们只会说一个进程占用了多少内存,而从来不会说一个线程占用了多少内存。资源归属于进程,线程却拥有资源的使用权。
线程的概念是建立在进程的基础上的,一个进程至少有一个主线程,有0个或多个子线程,这些线程共用这个进程所申请的资源,因此才会有线程间同步与资源互斥这些概念。由于进程已经是资源分配的单位,因此,进程与进程之间都是相互隔离的,就如同一家一户,各有各的围墙,各有各的宅基地,线程如同家庭里的亲人,这些亲人共同使用家里的资源。
本质上,是线程在执行,进程只是负责申请资源,因此线程才是操作系统调度的最小单位。对于操作系统来说,在进程之间进行切换,就如同从一个住宅切换到另一家住宅,而在线程间切换,就如同从房子的一间卧室切换到客厅。线程间切换要比进程间切换容易的多。
2. 什么是协程
进程,线程是大家非常熟悉的概念,然而说到协程,很多人表示懵逼了,关于协程,要准确掌握以下两个概念
- 协程在一个线程中存在
- 协程不是系统调度的,而是程序自己负责调度
协程是线程的异步编程模型,因此我才说,协程在一个线程中存在,我特意强调一个线程,是想让你明确一点,系统并没有创建出若干个协程来进行工作,在这个线程中,存在多个子程序,假设有子程序A,B,C,那么最初是A在执行,中途遇到了IO,于是停止A,执行B,然后B中也遇到了IO,这个时候再回来执行A,A执行结束后再执行C
你会看到,在一个线程内,A,B,C三个子程序互相协调工作,这个就是协程。这里所谓的子程序,你可以理解为函数,但是执行过程又不是函数之间的调用,因为代码里,这三个函数并不存在调用关系,他们可能都是在爬取一个url里的内容,各自的运行是独立的,但是子程序在执行过程中发生了中断,将控制权交出,在适当的时候返回来继续执行。
2.1 和线程的对比
线程是系统创建的,具体什么时候执行,执行多久,都是由系统决定的,而协程则是程序自己创建的,在python中,yield 和gevent都可以实现协程。
python的多线程由于存在GIL锁,因此一个时刻只有一个线程在运行,如果你起了10个线程,那么CPU要在这10个线程之间不停的切换,每个线程都有自己的一组CUP寄存器,这里保存了线程的上下文,线程之间的切换是会耗费资源的,线程越多,切换的越频繁,耗费的资源也就越多。
协程之间也存在切换,但是这些协程都是在一个线程中,由程序自身负责切换,而不是CPU负责切换,这种切换相比于线程之间的切换就快的多了,协程拥有自己的寄存器上下文和栈,当需要切换时,将这些内容保存到其他地方,需要切换回来时,将这些内容回复回来,找到上一次离开时所处的逻辑流位置并继续执行。
线程之间对共享资源的访问必须加锁,但协程不需要,原因很简单,协程始终生存在于一个线程中,根本不存在同时修改一个共享资源的情况。
协程是在线程层面上进行了拆分,与线程相关的是抢占式多任务,与协程相关的是协作式多任务。
如果没有协程,当一个线程内遇到IO等待时,会切换到别的线程去执行,但是有了协程,一个线程内的某个子程序遇到IO等待时,会将控制权交给同在线程内的其他子程序,没有了线程之间的切换,没有了锁,效率自然变高了。
python进程杂谈
- python进程杂谈
- 给进程命名
- 杀掉一个进程
- 子进程在后台运行
- 使用队列交换对象
1. 给进程命名
我们可以给进程起一个名字,这样在debug的时候能够提供一些帮助
import multiprocessing |
程序输出结果
test |
如果程序没有主动为进程起一个名字,那么会默认为进程分配一个名字。
2. 杀掉一个进程
杀掉进程可以使用terminate方法,假设有这样的需求场景,进程启动后,我们希望5秒钟后不论程序执行结果如何都将其杀死,那么就可以这样来设计,使用Process创建一个子进程p,随后启动一个线程来检查时间和进程p的状态,5秒钟过后,在线程中调用进程的terminate方法将其杀死,示例代码如下
import multiprocessing |
- is_alive可以检查进程是否存活
- exitcode 是进程退出的状态码,如果是0表示正常退出,大于0表示进程有错误,小于0表示被对应的信号杀死。
3. 子进程在后台运行
首先要明确一点,后台进程不是守护进程或者服务,如果需要处理的任务比较大同时又不需要人工干预,那么可以将其设置为后台进程
import multiprocessing |
只需要将daemon设置为True,进程就变为后台进程,与非后台进程相比有以下几点不同:
- 后台进程不会在终端输出任何信息,非后端进程则会输出print里的内容
- 后台进程不允许再启动子进程,因为后台进程会在主进程结束退出,非后台进程则没有这样的限制
4. 使用队列交换对象
进程间通信可以使用队列,Queue返回一个进程共享的队列,它既是线程安全的也是进程安全的。任何可以序列化的对象都可以通过它来传输。在下面的示例中,主进程中有一个列表lst,里面存储了10个任务,启动两个子进程,主进程与子进程通过队列来交换数据
import multiprocessing |
程序输出结果
进程Process-1处理任务1 |
使用concurrent.futures 模块提供的进程池进行并发
concurrent.futures 从python 3.2 版本被加入到发行版中,它提供了线程池和进程池,具有管理并行编程任务、处理非确定性的执行流程、进程/线程同步等功能, 它的submit和map方法可以让你快速的实现多进程并发。
使用进程池,你无需关心进程的创建与销毁,结果的收集,使用起来极为方便,下图是对进程池工作原理的解释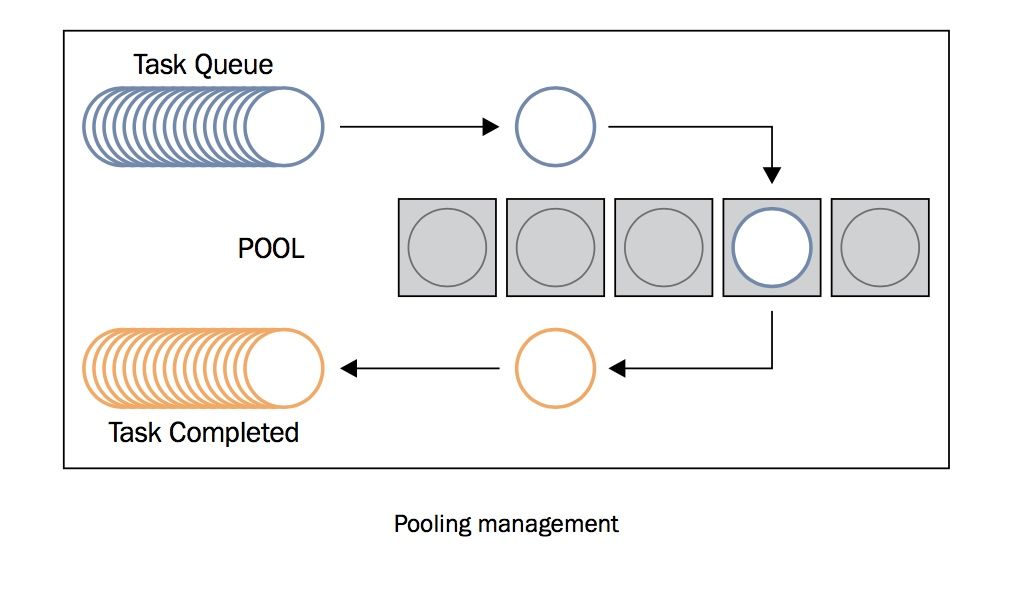
1. 使用submit提交任务到进程池
假设你有1000个url需要进行爬取,这类任务十分适合使用多线程处理,本示例仅是为了展示进程池如何使用,实践中,这类IO密集型任务应当使用多线程进行并发处理,CPU密集型任务则应当使用多进程并发处理。让我们看看使用concurrent.futures 提供的进程池该如何进行并发。
import time |
进程池只是提供了并发的机制,你需要自己完成并发时需要调用的函数,这里指的是crawl, 它完成单次任务,爬取一个url并返回结果。
第1步创建进程池, max_workers 定义了进程池的大小
with concurrent.futures.ProcessPoolExecutor(max_workers=30) as executor: |
第2步,向进程池提交任务
futures = [executor.submit(crawl, url) for url in urls] |
调用executor 的submit方法,第一个参数是在进程中需要被执行的函数,从第二个参数开始是函数所需要参数。futures 里存储的并不是最终的结果,而是future对象,要等到进程执行函数有了返回值以后才能调用result方法获得返回结果。
第3步,等待返回结果
for future in concurrent.futures.as_completed(futures): |
你不必关系哪个进程完成了一次crawl函数的调用,as_completed方法会帮你识别出已经完成的任务,调用result方法即可获得crawl函数的返回值。
这里要特别强调一点,crawl_result存储的数据与urls 之间是不存在依据索引位置的一一对应关系的,在代码里,我输出了crawl_result前10个元素
[0, 16, 6, 5, 3, 4, 2, 15, 14, 13, 12, 11, 10, 9, 8, 7, 1, 18, 20, 22] |
显然,与urls之间毫无关联关系,urls中的0是最先被提交的,但未必是最先完成的,因此这两个列表的索引是不能最为输入与输出之间的映射关系的。如果想要在他们之间建立某个联系,建议在crawl 函数的返回值中加入输入的参数url , 根据这个url 就能够找到对应的urls中的输入信息。
2. 使用map方法并发执行任务
map 与 submit 的最显著的区别在于,map方法返回的结果是有序的
import time |
map方法会遍历urls,传入crawl 函数进行调用,返回的结果res是一个生成器,其结果是有序的,使用list方法将生成器转为列表,输出前20个元素
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19] |
这与urls的前20个元素是一一对应的。