常用模块导读
python提供了非常多的标准模块,这些模块实现的都是很具体的你一定会经常使用的模块,掌握这些模块,可以让你在解决问题时思路更广,效率更高,本章节,你将学习以下标准模块:
- os
- sys
- math
- random
- hashlib
- statistics
- uuid
os
os是python的内置模块,它提供了与操作系统相关的接口,可与操作系统进行交互,例如对系统文件目录的操作,新建,修改,删除文件夹和文件,os.system可以执行系统命令。
1. 系统操作相关
1.1 os.sep
操作系统路径分隔符,在不同的操作系统上,路径分割符是不一样的。windows系统是\, linux系统和mac是/
1.2 os.name
获取正在使用的工作平台,windows下是nt,linux/unix环境下是posix
1.3 os.getenv()
读取环境变量
1.4 os.getcwd()
获取当前工作路径
1.5 示例代码
import os |
2. 目录操作
对文件夹进行增删改查操作
2.1 os.listdir()
获取指定目录下的所有文件和目录名,如果不指定目录,则目录默认为当前所在目录
import os |
2.1 os.mkdir()
创建一个目录(文件夹)
import os |
2.2 os.rmdir()
删除一个目录,如果目录里有文件,则无法删除
import os |
2.3 os.makedirs()
生成多层递归目录,这个方法与mkdir一样,都可以创建目录,不同之处在于mkdir只能创建一层目录,而makedirs可以创建多层。比如你想在目录A下创建一个目录B,用着两个方法都可以,但如果想在A目录下创建一个多层目录C/D/E, 就只能用os.makedirs().它会先创建C,然后在C下面创建D,在D下面创建E
import os |
2.4 os.removedirs()
递归删除多层目录,但若干目录中有文件则无法删除
import os |
2.5 os.chdir()
改变当前目录,切换到其他目录,和linux系统下的cd 命令是同样的效果
2.6 os.rename()
修改目录或者文件的名字
import os |
将文件demo.py修改为demo2.py
3. path模块
os.path提供了对文件和目录更加强大的操作
| 方法名 | 功能作用 |
|---|---|
| os.path.exists(path) | 判断path是否存在,path既可以是目录,也是是文件,如果存在返回True,反之返回False |
| os.path.isfile(path) | 判断path是否是文件,如果是返回True |
| os.path.isdir(path) | 判断path是否是目录,如果是返回True |
| os.path.isabs(path) | 判断路径是否是绝对路径 |
| os.path.basename(path) | 获取文件名 |
| os.path.dirname(path) | 获取路径名 |
| os.path.getsize(path) | 获取文件大小 |
| os.path.getatime(path) | 获取最近访问时间 |
| os.path.getctime(path) | unix是最新的元数据更改的时间,windows系统下是文件创建时间 |
| os.path.getmtime(path) | 获取文件内容最近修改时间 |
| os.path.abspath(path) | 获取绝对路径 |
| os.path.split(path) | 分割路径 |
| os.path.splitext(path) | 分割文件名,返回由文件名和扩展名组成的元组 |
| os.path.join() | 拼接路径 |
示例代码
import os |
程序输出结果
test.py |
sys
sys是python的内置模块,它包含了python解释器和系统环境有关的参数和函数,例如sys.stdin, sys.stdin, sys.stderr 是与解释器的标准输入,输出和错误流相对应的文件对象, sys.argv可以获取外部向程序内部传递的参数。
1. sys.version
获取python的版本
import sys |
2. sys.stdin, sys.stdin, sys.stderr
这三者是与解释器的标准输入,输出和错误流相对应的文件对象。关于这三个文件对象足以专门写一篇教程,这里只举一个例子来说明sys.stdout的作用
import sys |
sys.stdout是标准输出流,上面的代码将标准输出流重定向到一个打开的文件中,这样print函数在执行时,就不会在终端输出内容,而是在将内容写入到文件中
3. sys.modules
sys.modules是一个全局字典,该字典是python启动后就加载在内存中。每当程序员导入新的模块,sys.modules将自动记录该模块。当第二次再导入该模块时,python会直接到字典中查找,从而加快了程序运行的速度
4. sys.path
获取指定模块搜索路径的列表,当你在程序中使用import关键字引入一个模块时,解释器会按照一定的顺序来查找这个模块
- 当前目录
- 如果不在当前目录,Python 则搜索在 shell 变量 PYTHONPATH 下的每个目录。
- 如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/
模块搜索路径存储在 system 模块的 sys.path 变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录
5. sys.exit(n)
程序执行到代码末尾,解释器会自动退出,如果你希望中途退出程序,可以使用sys.exit()方法,n可以传入一个整数,你可以在主程序中捕获对sys.exit()的调用并获得这个n,一般0表示正常退出,其他为异常
import sys |
程序输出结果是 3
6. sys.argv
在外部向程序内部传递参数,定义一个名为test.py的脚本,内容如下
import sys |
这段代码看起来有点怪怪的,sys.argv到底是什么东西,别急,要想理解这段代码,就必须在终端通过python命令来运行程序
python3 test.py 接收参数 2 |
在使用python命令执行脚本时,脚本的后面还跟了两段内容,这就是在向程序传递运行时所需要的参数,sys.argv就是用来存储这个参数的
程序输出内容为
['test.py', '接收参数', '2'] |
sys.argv是一个列表,包含了脚本的名称后紧跟在脚本后面的参数
math
math模块提供了很多与数学相关的函数,本教程只列举了其中一部分。
| 方法名 | 功能和作用 |
|---|---|
| math.ceil(x) | 取大于等于x的最小的整数值,如果x是一个整数,则返回x |
| math.fabs(x) | 返回x的绝对值 |
| math.floor(x) | floor()取小于等于x的最大的整数值,如果x是一个整数,则返回自身 |
| log(x,a) | 如果不指定a,则默认以e为基数,a参数给定时,将 x 以a为底的对数返回 |
| math.log10(x) | 返回x的以10为底的对数 |
| math.log2(x) | 返回x的基2对数 |
| math.pi | 数字常量,圆周率 |
| math.pow(x, y) | 返回x的y次方,即x**y |
| math.sqrt(x) | 求x的平方根 |
python随机数模块random
random是python的一个内置模块,专门用于生成随机数,但是要明确一点,random模块生成的并非真正的随机数,而是伪随机数。random提供的部分方法可以生成指定分布的随机数,比如生成符合高斯分布的随机数,这些方法在处理数学问题时将非常有用。
1. 随机数种子
random模块生成的都是伪随机数,具体生成的随机数是什么取决于随机数种子,当随机数种子相同时,生成的随机数也就相同。使用seed方法可设置随机数种子。
import random |
这段代码,不论谁执行,在哪里执行,生成的随机数都是80,因为随机数种子都是5,如果使用seed方法设置随机数种子或者seed方法在调用时不传参数,则使用系统当前的时间来作为随机数种子,这也是我们平常所采用的方法,不设置随机数种子。
某些情况下设置随机数种子,是为了让某个包含了随机数的算法能够有相同的结果,这样便于验证算法的正确性。
2. 生成指定分布的随机数
random模块的一些方法可以生成符合指定分布的随机数,比如random.gauss
def gauss(self, mu, sigma): |
- mu 是平均值
- sigma 是标准差
下面的代码生成10000个符合平均值为3标准为1的随机数并绘制出直方图。
import random |
除了高斯分布以外,random还支持生成指数分布,Gamma 分布等其他分布的随机数,在实践中,这类方法极少使用,因此不做过多介绍。
3. 随机生成整数的方法
3.1 random.randint(a, b)
random.randint方法返回一个随机整数N,N满足条件a <= N <= b
import random |
3.2 random.randrange
random.randrange方法的应用与内置函数range有一点关联,randrange会从range函数返回的整数序列中随机返回一个整数。
random.randrange方法语法
random.randrange(stop) |
range(stop)产生一个从0到stop-1的整数序列seq,random.randrange(stop)从seq里随机选择一个数做为返回值,random.randrange(stop)等价于random.randint(0, stop-1)。
range(start, stop[, step]) 以step为步长从start开始到stop结束产生一个序列seq,random.randrange(start, stop[, step])从seq里随机选择一个数做为返回值。
示例代码
>>> random.randrange(100) |
3.3 random.getrandbits(k)
random.getrandbits(k)返回具有k个比特位的随机非负整数,以random.getrandbits(3)为例,一个整数有3个比特位,那么最大值的二进制形式为111,最小值的二进制形式为000,转换为10进制,随机数最大值是7,最小值是0。
random.getrandbits(3) |
4. 生成随机浮点数
4.1 random.random()
random.random()方法返回一个在 [0.0, 1.0)范围内的浮点数,示例代码
import random |
4.2 random.uniform(a, b)
random.uniform 方法返回一个随机数N,当a <= b时,N满足条件a <= N <= b, 当a > b时,N满足条件b <= N <= a
random.uniform(1.2, 4.5) |
uniform 对a,b两个参数的大小关系没有要求,通常人们会猜测a应当小于等于b,但实际上a可以大于b。
5. 从序列里随机选取对象
5.1 random.choice(seq)
random.choice方法从序列seq中随机返回一个对象,如果序列为空,则引发IndexError
random.choice([1, 4, 5, 6]) |
5.2 random.choices
random.choices方法语法
random.choices(population, weights=None, *, cum_weights=None, k=1) |
random.choices方法从序列population中随机选取k个对象,如果指定了weights,则根据权重返回对象,权重越大,被随机选中返回的概率越大。返回的k个随机对象可以有重复对象,这一点一定要注意。
参数解释
- population 序列
- weights 相对权重
- cum_weights 累积权重
- k,返回对象的个数
示例代码
不设置权重
import random |
设置相对权重
import random |
weights里的对象个数必须与fruits里的对象个数相同,weights表示的是各项之间被选中的概率相对比值,苹果被随机选中的概率是50%,计算方法是5/(5+2+2+1)。
设置累积权重
import random |
choices 在处理权重时,会自动将相对权重转换为累积权重,weights=[5, 2, 2, 1]转为为累积权重为cum_weights=[5, 7, 9, 10],每一项的值都是前面几项的和。
累积权重不如相对权重好理解,所以建议你使用相对权重。
5.3 random.sample
random.sample方法从序列中随机选取k个对象,选出的对象都是唯一的,sample用于无重复的随机抽样,smaple方法语法
def sample(self, population, k): |
参数说明
- population 序列
- k 抽样个数
如果population本身就包含了重复元素,sample方法每次返回的对象都是样本中可能的选择。
import random |
5.4 random.shuffle
random.shuffle方法将序列就地大乱,这类似于我们娱乐时的洗牌。
import random |
经shuffle方法处理后,lst列表变得无序。
hashlib
1. md5
hashlib提供了常用的摘要算法如MD5,SHA1等等,摘要算法又称散列算法,哈希算法。很多人把MD5说成是加密算法,这是极其不准确的,md5是散列算法,不是加密算法,你什么时候见过有人能把所谓“加密”的值解密成原文? 很多网站的密码都是经过md5散列处理的,为的是保护用户账号的安全,但太多的人就是喜欢用简单的密码,比如123456,而123456 经过MD5散列后的值永远是 e10adc3949ba59abbe56e057f20f883e ,于是黑客就通过撞库,得到了用户的密码,网上一些所谓“解密”MD5的网站,仅仅是收集了大量的散列后的值而已,不是解密,而是撞库
2. python3 里使用md5
import hashlib |
程序输出结果
MD5散列前为 :123456 |
statistics
statistics 提供了一些计算数学统计量的函数,功能如下表所示
| 函数 | 功能 |
|---|---|
| mean | 算数平均值 |
| harmonic_mean | 调和平均值 |
| median | 中位数 |
| median_low | 数据的第一个中位数(总数为偶数时有两个中位数) |
| median_high | 数据的第二个中位数 |
| median_grouped | 分组数据的中位数的均值 |
| mode | 离散数据的模式, 数据中最常见的值 |
| pstdev | 数据总体的标准差 |
| pvariance | 数据总体的方差 |
| stdev | 数据样本的标准差 |
| variance | 数据样本的方差 |
示例代码如下
import statistics |
uuid
uuid 是通用唯一识别码,它通过MAC地址、时间戳、命名空间、随机数、伪随机数来保证生成ID的唯一性,理论上,在这个宇宙中不可能生成两个相同的uuid。在分布式系统中,你可以用uuid来唯一的表示一个元素,不需要中央控制端来做标识的统一分配,任何一台机器上都可以大胆放心的生成uuid。
在很多系统里,uuid都有应用,比如微软的 Microsoft’s Globally Unique Identifiers (GUIDs),Linux ext2/ext3 档案系统。我在工作中也曾用到过,在于其他web服务交互时,使用uuid作为一次请求的唯一标识,在日志中记录下来,这样就可以通过uuid来串联起两个系统的调用链路信息。
uuid的算法有5种:
- uuid1(), 基于时间戳, 由MAC地址、当前时间戳、随机数生成,可以保证全球唯一性
- uuid2(), 基于分布式计算环境DCE,python中没有提供这个算法。
- uuid3(),计算名字和命名空间的MD5散列值,可以保证同一命名空间中不同名字的唯一性,和不同命名空间的唯一性,但同一命名空间的同一名字生成相同的uuid
- uuid4(), 由伪随机数得到,有一定的重复概率,该概率可以计算出来
- uuid5(),基于名字的SHA-1散列值, 算法与uuid3相同,不同的是使用 Secure Hash Algorithm 1 算法
uuid3() 和 uuid5() 不常用,工作中使用uuid1()和uuid() 就可以了
import uuid |
pathlib — 面向对象的文件系统路径
1. pathlib 取代os.path模块
从python3.4开始,pathlib正式成为标准库,旨在取代老旧的os.path模块和一些os模块中对系统路径的操作。pathlib提供了表示文件系统路径的类,而os.path提供的是各种操作路径的函数,如果你已经熟练的掌握了os.path,那么学习pathlib将非常容易。
从使用情况来看,pathlib的功能对编程人员更加友好,对系统路径的操作更便捷。
2. 纯路径与具体路径
下图是pathlib所提供的类的继承关系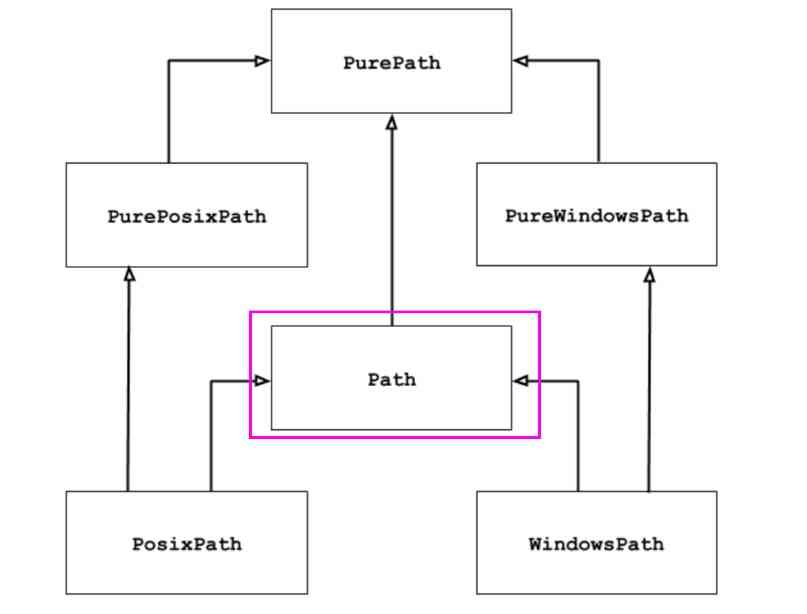
纯路径与具体路径的区别在于,具体路径类可以对系统路径进行I/O操作,而纯路径则不可以,那么纯路径类能做什么呢?纯路径类可以对路径进行计算,这种计算不涉及I/O操作,比如获得文件的后缀
from pathlib import PurePath |
获得文件路径的后缀,纯粹是一个字符串计算的操作,不涉及到I/O操作,如果你对路径的操作都属于这种类型的,那么用纯路径类就可以。那么,具体路径的所谓I/O操作是什么呢,举一个简单的例子,判断路径是否存在。想要判断一个路径是否存在,就一定需要访问操作系统,只有操作系统才知道一个路径是否存在。在上面的代码里,你不能用path对象去调用exists方法,因为PurePath类根本没有这个方法,你需要使用Path类才可以
from pathlib import Path |
PurePath 是Path的父类,因此如果你分不清该用纯路径类还是具体路径类,那么使用Path类就好了。至于PosixPath 和 WindowsPath,如果你也分不清应当依据什么进行选择,那就不要选了,一劳永逸的选择Path就好了,python会根据你的系统自动为你选择。上面的代码,如果在windows平台上执行,path.class 的值是pathlib.WindowsPath, 如果是在linux系统上执行,path.class 的值是pathlib.PosixPath。
3. pathlib方法与os.path函数对照关系
如果你对os.path比较熟悉,那么在学习pathlib时,可以参考下表中方法与函数的对照关系
4. 用的比较爽的方法
4.1 获得上层文件夹
在工程上,你可能需要通过当前的一个已知路径,向上回去几层,去定位一个文件夹或者文件,比如给定一个路径 /home/root/python/1.txt,向上回溯两层,得到的路径是/home/root,使用os.path模块,你可以这样编写代码
path = os.path.dirname('/home/root/python/1.txt') |
向上回溯N层,需要调用N次dirname函数,着实麻烦,如果用pathlib,简直不要太简单
from pathlib import Path |
回溯3层,取path.parents[2]即可,怎么样,是不是方便了许多。
4.2 遍历文件夹及其子文件夹
使用os.walk函数,可以实现对文件夹的深层遍历
for dir_path,subpaths,files in os.walk('./',False): |
上面的代码,可以输出当前目录下所有的文件夹和文件,如果只想要某种后缀的文件,那么需要你对file_path的后缀进行判断,而使用Path的glob方法,将更加容易。
py_files = path.glob("**/*.py") |
“**” 是递归通配符,意味着对当前目录和子目录进行递归遍历,*.py 会匹配所有以.py结尾的文件路径。
os.path模块
os.path模块是Python专门用于处理系统路径的模块,路径包括文件和目录,路径是否存在并不影响模块里的函数正常运行,os.path甚至可以处理网站url,下表是os.path模块的常用函数
| 函数 | 功能 |
|---|---|
| os.path.normpath | 去除路径中多余的分隔符和对上级目录的引用,返回标准化的路径 |
| os.path.normcase | 返回大小写规范后的路径 |
| os.path.isabs | 判断一个路径是否是绝对路径 |
| os.path.isdir | 判断一个路径是否是文件夹 |
| os.path.isfile | 判断一个路径是否是文件 |
| os.path.islink | 判断一个路径是否是软链 |
| os.path.join | 将多个路径拼接到一起生成一个新的路径 |
| os.path.ismount | 判断一个路径是否是挂载点 |
| os.path.getsize | 返回目录或者文件的大小,单位是字节 |
| os.path.getctime | 返回路径或者文件的创建时间 |
| os.path.getmtime | 返回文件或者路径的最后修改时间 |
| os.path.getatime | 返回文件或者路径的最后访问时间 |
| os.path.expandvars | 根据真实的环境变量替换参数path路径中的环境变量部分并返回替换后的路径 |