Linux主机监控最佳实践
对于监控系统,基础功能的强弱确实非常关键,但是如何在不同的场景落地实践,则更为关键。在《监控实践》章节,搜罗各类监控实践经验,会以不同的组件分门别类,您如果对某个组件有好的实践经验,欢迎提 PR,把您的文章链接附到对应的组件目录下。
本文会同时介绍使用 夜莺 或 Flashcat(夜莺商业版)对 Linux 主机监控的最佳实践。涵盖内容:
- Agent 安装配置实践
- Agent 打标签
- 业务组划分实践
- 数据可视化仪表盘设计实践
- 关键监控指标
- 机器相关的告警规则配置
- 采集规则中心化管理
🎯 Agent 安装配置
虽然您可以使用市面上常见的采集器来对接夜莺和 Flashcat,不过要想有个丝滑的体验,机器监控的 Agent 首推 Categraf。
Categraf 是快猫星云主导的一款 Agent,旨在解决常见的组件监控和日志监控。其资料地址如下:
上面的安装文档已经说的非常清楚,这里不再赘述,核心就是下载相关平台的包,然后 sudo ./categraf --install 即可安装。
Categraf 要监控很多组件,所以有很多配置,其配置目录就是和二进制同级的 conf 目录。conf 内有一个主配置文件 config.toml,以及一堆 input. 打头的插件目录,主配置文件 config.toml 的说明文档如下,请一定要阅读:
https://flashcat.cloud/docs/content/flashcat-monitor/categraf/3-configuration/
注意,即便您只需要其中一个插件,也一定要先阅读上面提到的主配置说明,那是前置知识。
至于各个插件的能力和配置方式,有如下一些资料供您参考。
插件自身的配置注释
conf 下面的 input. 打头的各个目录下就是插件的配置,有的插件有多个配置文件,大部分只有一个配置文件。
注意,配置文件是可以切分的,对于某个插件而言,会把插件配置目录里的多个(如有)文件按照文件名排序,然后拼接在一起,当做一个大配置文件来读取,所以,插件目录里不能放置无关文件。
每个插件的配置目录里都提供了默认配置以及详尽的注释,通常来讲,只通过阅读这些注释,就可以了解个七七八八了。
插件说明文档
有些常用的插件,我们撰写了详细说明文档,地址如下:
https://flashcat.cloud/docs/content/flashcat-monitor/categraf/plugin/introduction/
如果上面两个资料仍然不够用,则需要阅读插件的 README 甚至代码了。
插件 README 和代码
Categraf 的各个插件的代码在这个总目录下:
每个插件是一个子目录,通常每个插件代码目录里会有一个 README,您可以阅读其 README 说明了解更多知识。
如果阅读了 README 还是不理解,那就需要阅读插件代码了,别怕,大部分插件的代码其实非常容易,只有一两个文件,交给 AI,很容易给你讲解透彻。
🎯 Agent 打标签
监控体系里,标签是一个非常关键的信息,用于做一些维度划分,除了 Zabbix、StatsD 这种非常老旧的监控系统,新的监控系统全部都可以很好的支持标签体系。
我们可以为 Categraf 打上标签,这样一来,Categraf 采集的所有监控数据都会附有这些标签,方便您后续的筛选分析、数据串联。
机器的标签如何划分?
通常来讲,机器的标签有两类,一类不常改变,贯穿机器的整个生命周期,比如机器所在的机房信息、Region 信息甚至 ENV 信息,这类信息,建议直接配置到 Categraf 的 config.toml 中的:
[global.labels] |
通常在使用 Ansible 批量安装 Categraf 的时候直接生成这个配置即可。
global.labels 中的标签支持 $hostname 和 $ip 两个特殊变量,如果在标签值的字符串中包含了这俩变量,运行时会被自动替换为本机的 Hostname 和 IP。
除了 global.labels 中的不常变化的标签,机器还有一个 hostname 属性也极为关键,hostname 属性的值是作为机器的唯一标识来对待。
在 config.toml 中,我们通过注释的方式详细解释了 hostname 字段的配置,这里不再赘述。
hostname 字段也可以引用 $hostname 和 $ip 这两个特殊变量。那最佳配置实践是什么?
我们的建议是直接配置 hostname="$hostname-$ip",确保各个机器的标识信息不同,且含义丰富。而 global.labels 中就不需要重复配置 Hostname 和 IP 相关的信息了。
hostname 信息也会被作为机器监控数据的一个标签,标签 Key 为 agent_hostname,比如通过测试模式(测试模式不会上报监控数据给服务端)我们来看一眼采集到的数据:
[root@dev-n9e-01 ~]# ./categraf --test --inputs mem | grep mem |
从输出中可以看到,采集的监控指标中包含一个 agent_hostname 的标签,其值就是 config.toml 中的 hostname,我配置的 hostname=$hostname-$ip,所以拿到的最终结果是:agent_hostname=iZ2ze4oi71k3qgdxwsyn07Z-10.99.1.107。这个数据如果直接上报给 Prometheus 或 VictoriaMetrics 等 TSDB,这个 agent_hostname 标签会被原封不动保留,如果 Categraf 把数据推给夜莺服务端(或 Flashcat 服务端),再由服务端转存到时序库,服务端会提取 agent_hostname 的值作为机器标识写入 DB 中,进而你就可以在机器列表中看到这个机器了,同时服务端会把 agent_hostname 这个标签 rename 为 ident,后续查看监控数据时请注意。
通常来讲,我们建议您让 Categraf 把数据推给夜莺或 Flashcat 的服务端,而非直接写入 TSDB。因为服务端生成机器列表之后,就可以对机器额外打标签、划分业务组,方便您管理。
即,机器共有两种分类方式:
- 标签。包括 config.toml 中打的一些相对固定的标签,以及页面上给机器打的一些标签。其实通常来讲,标签只是在 config.toml 中打,就足够用了,但是有些公司情况特殊,不方便登录机器,此时可以在页面上给机器打标签。不管是通过什么方式打的,标签都希望是一些不常变化的信息,因为标签一旦变化,就意味着时序数据的标签变化,时序数据是以标签为标识的,标签变了,就表示老数据断了,同时生成了新数据。
- 业务组。相比标签,业务组对机器的分类可以变动更频繁,另外新版本支持把机器挂到多个业务组,也解决了多个服务混部在一台机器上想让机器同时属于多个业务组的场景。
🎯 业务组划分实践
业务组的划分,建议颗粒度到服务层级,同时业务组名称中体现组织架构层级。比如:
hosta、hostb 两台机器,用于部署业务 A 的 MySQL 服务,hostc、hostd 两台机器,用于部署业务 B 的 MySQL 服务,则可以划分为两个业务组:
DBA/MySQL/BizA -> [hosta、hostb] |
DBA/MySQL/BizA 这个业务组的名称相当于包含了三种信息:
- DBA:隶属于 DBA 大团队
- MySQL:部署的 MySQL
- BizA:用于 业务 A
业务组名称中的这三个信息故意使用 / 分隔了一下,后面就可以让页面展示业务组的时候,展示为树形结构,更方便查看。分隔符推荐使用 /,但不是必须的,您可以选择其他分隔符,在站点设置中可以调整。
服务信息到底是通过标签体现还是通过业务组体现?
看起来,标签和业务组都可以体现分类信息,那服务信息为啥要用业务组体现?而非使用标签体现?
其实关键决策因素是是否混部。如果你的机器上面混部了多个服务,就没法用标签了,比如某个机器混部了 n9e 和 mysql,你肯定想给机器打两个标签:
service=n9eservice=mysql
但是这俩标签的 Key 相同,而标签信息是要附加到时序数据中的,在 Prometheus 中多个标签不允许出现同 Key 的情况。
如果你的机器都是专用的,每个服务所用的机器不同,相互不影响,则亦可以使用标签分类,这种情况下你甚至全局只有一个业务组都是可以的。
🎯 可视化仪表盘
机器列表里自带了一些基础信息,不过那个价值不太大,一般都是使用仪表盘查看详细数据。
好的仪表盘设计,至少是一个总分结构,即:
- 第一个仪表盘:呈现 Overview 信息,通常是一个表格,表格里放置了要监控的目标对象的关键指标,点击其中一个监控对象,跳转到详情页面,即第二个仪表盘
- 第二个仪表盘:呈现监控对象的 Detail 信息
下面是机器的 Overview 大盘:
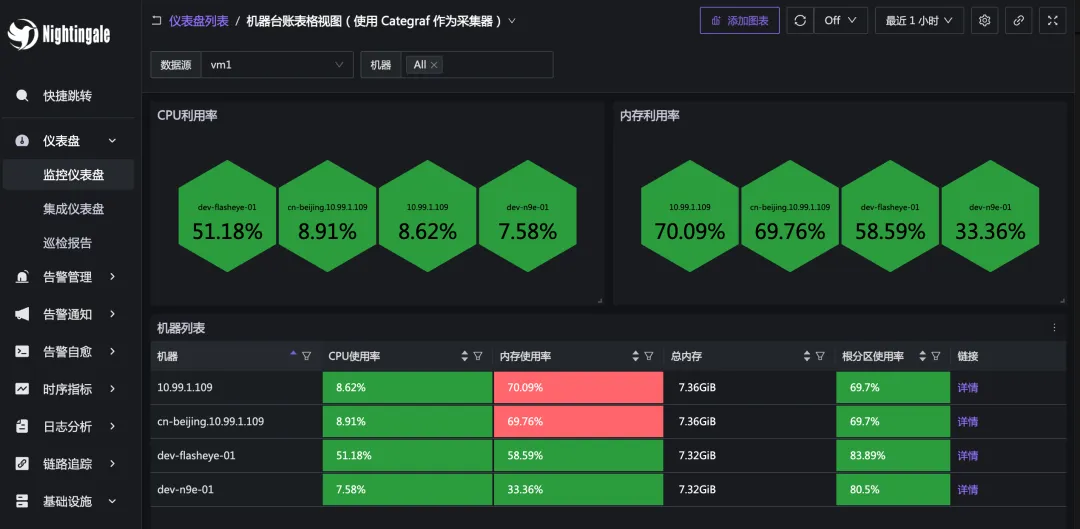
大盘 JSON 链接:
https://github.com/ccfos/nightingale/blob/main/integrations/Linux/dashboards/categraf-overview.json
下面是机器的 Detail 大盘:
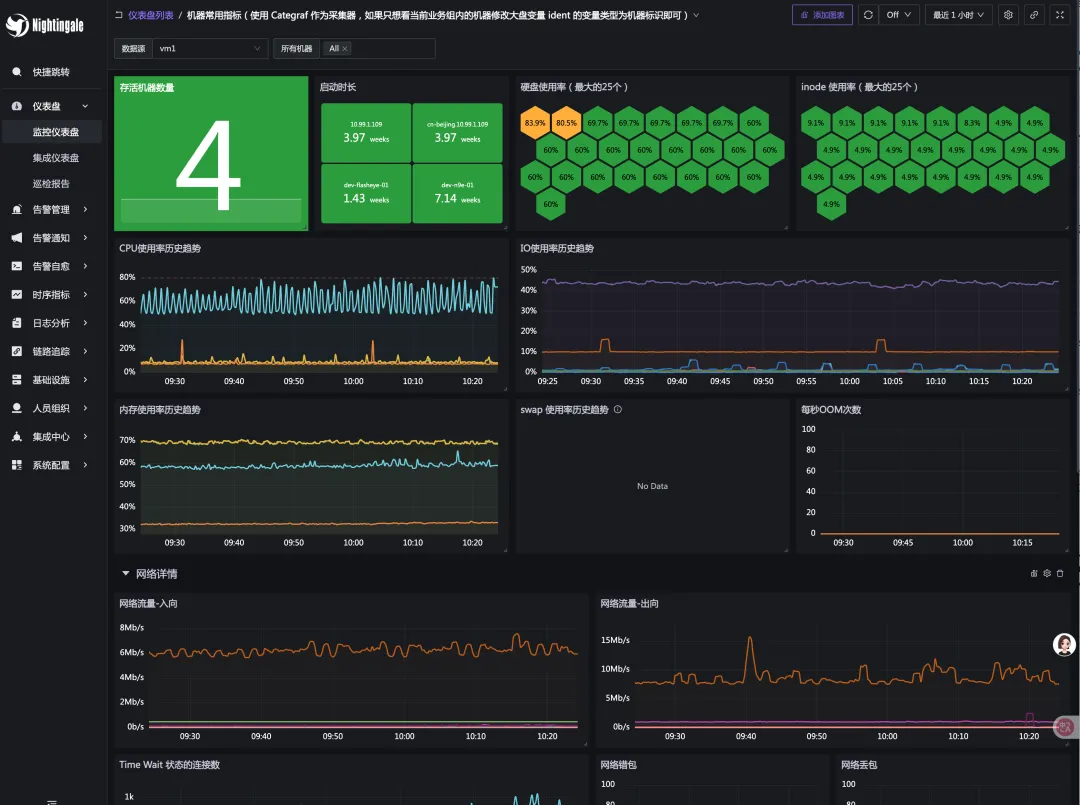
大盘 JSON 链接:
https://github.com/ccfos/nightingale/blob/main/integrations/Linux/dashboards/categraf-detail.json
🎯 关键指标
机器的关键指标其实都已经放到 Detail 大盘里了,无非就是:
- CPU、内存、IO、磁盘、inode 使用率
- OOM 次数(高版本内核才有这个指标)
- Swap 使用(通常生产环境不应该用 Swap)
- 网卡错包、丢包(有时网络慢就是这个导致的)
- 硬盘读写是否出错
- Conntrack 使用率(如果限制的太小,有时也会影响网络)
- 文件句柄:一个是系统层面的限制,一个是进程的 ulimit,还有 systemd、supervisord 对进程的限制,都应该注意
- Processes 总量,比如 cron 写挫了,生成了很多进程都没退出
- NTP 时间偏移量,现在IT中分布式系统很多,对时间校准要求很高
🎯 告警规则
Categraf 的常用机器告警规则,可以从下面找到:
告警这里,会有一个实践问题。是各个团队自己管自己的机器告警?还是运维团队统一管理,各个团队分别订阅自己感兴趣的告警?
其实都行,不同的公司会选择各自不同的实践。比如有些公司的某些研发团队,压根没有对口的运维人员,那就自己管理相关的机器告警规则了。创建一个独属于自己的业务组,然后编写独属于自己的告警规则即可。
各管各的
比如下面的告警规则配置:
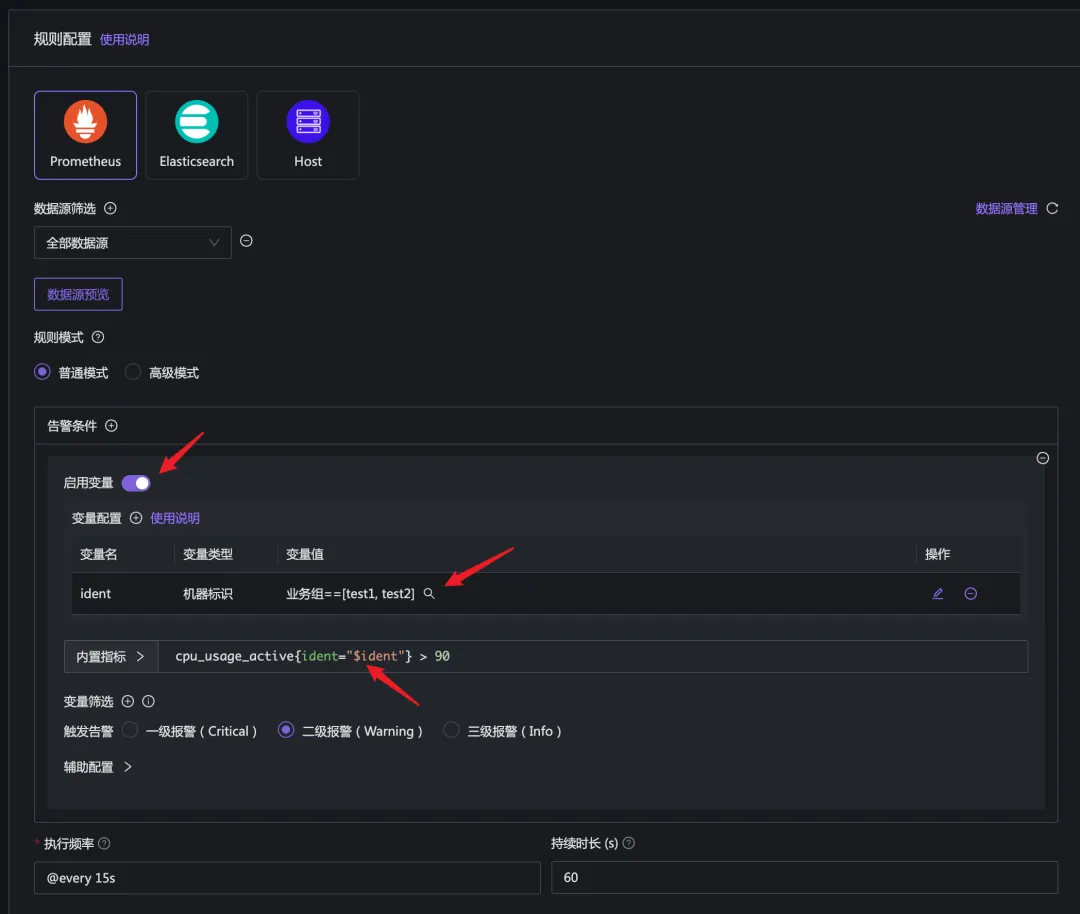
这里我启用了变量,配置了一个 ident 变量,类型是机器标识,变量值选择了两个业务组 test1 和 test2,在 promql 中引用了 $ident 作为筛选条件,最终达到的效果就是:只针对 test1 和 test2 这俩业务组内的机器,执行这个告警规则。
还有另一个配置,promql 那里不启用变量,只是简单的配置:
cpu_usage_active > 90 |
然后在规则下面有个 仅在本业务组生效 的配置,勾选之,则可以做到只对本业务组内的机器生效的效果。
但是这里有个局限,就是 promql 生成的告警规则必须包含 ident 标签,否则系统无法判定告警事件跟哪个机器相关。
运维统一管
运维人员可以统一配置一套告警规则,对所有机器生效( promql 不加任何筛选过滤条件,就是对 TSDB 中的所有监控数据生效)。
告警的时候发给运维人员的统一的一个通知规则,运维人员作为 owner 去处理。
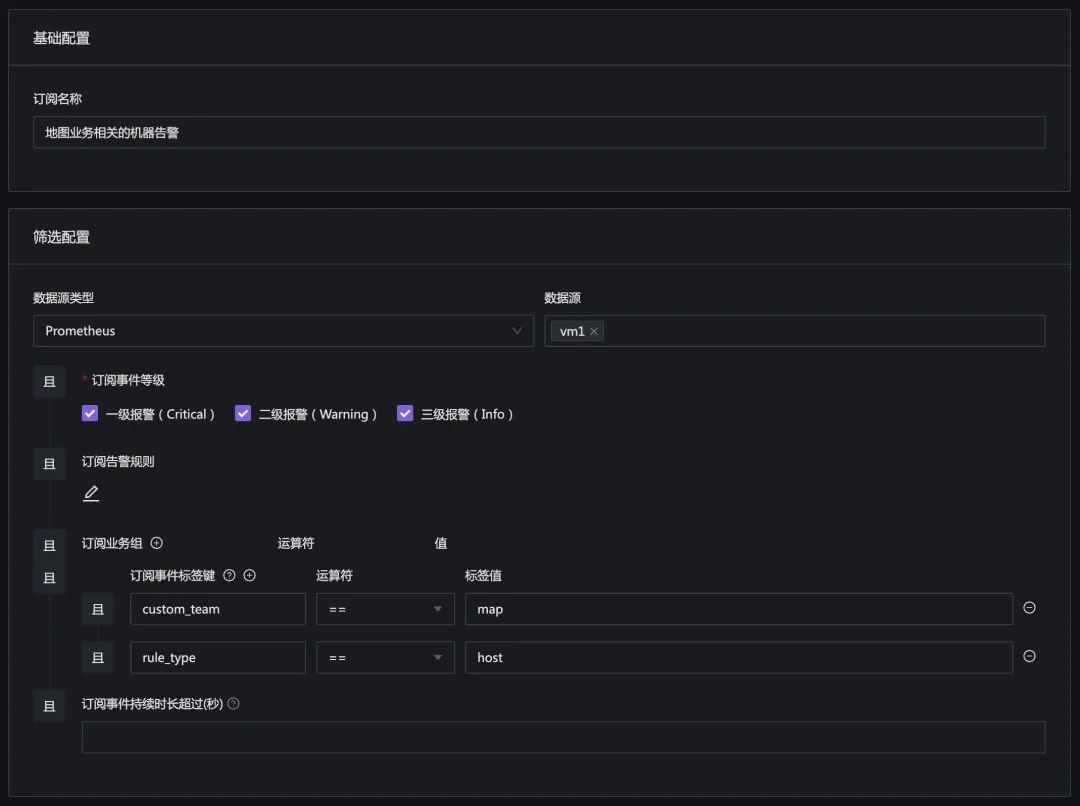
如果某个研发团队也关注自己相关的机器,那就使用订阅规则,去订阅自己感兴趣的告警即可。当然,这需要告警事件中有一些区分信息,否则订阅规则里无法过滤自己感兴趣的告警事件。
目前的版本,建议使用标签方式,给机器增加一些业务、服务信息,之后在订阅规则里,就可以根据标签来筛选自己感兴趣的机器的告警事件。
🎯 采集规则中心化管理
最后简单讲讲 Categraf 的采集规则中心管理功能。对于开源版本,直接去修改 conf 目录下的各个插件的配置即可,几乎所有的开源 agent 都是提供的这种管理方式。
如果有批量管理的需求,可以使用 Ansible 之类的批量管理。
商业版做了一些增强,可以在 Web 上统一中心化管理采集规则,然后下发给指定的机器。这样可以更为方便。另外有些公司要求比较严格,登录机器都费劲,这种中心化管理采集规则的方式则比较实用。
采集规则的配置样例如下:
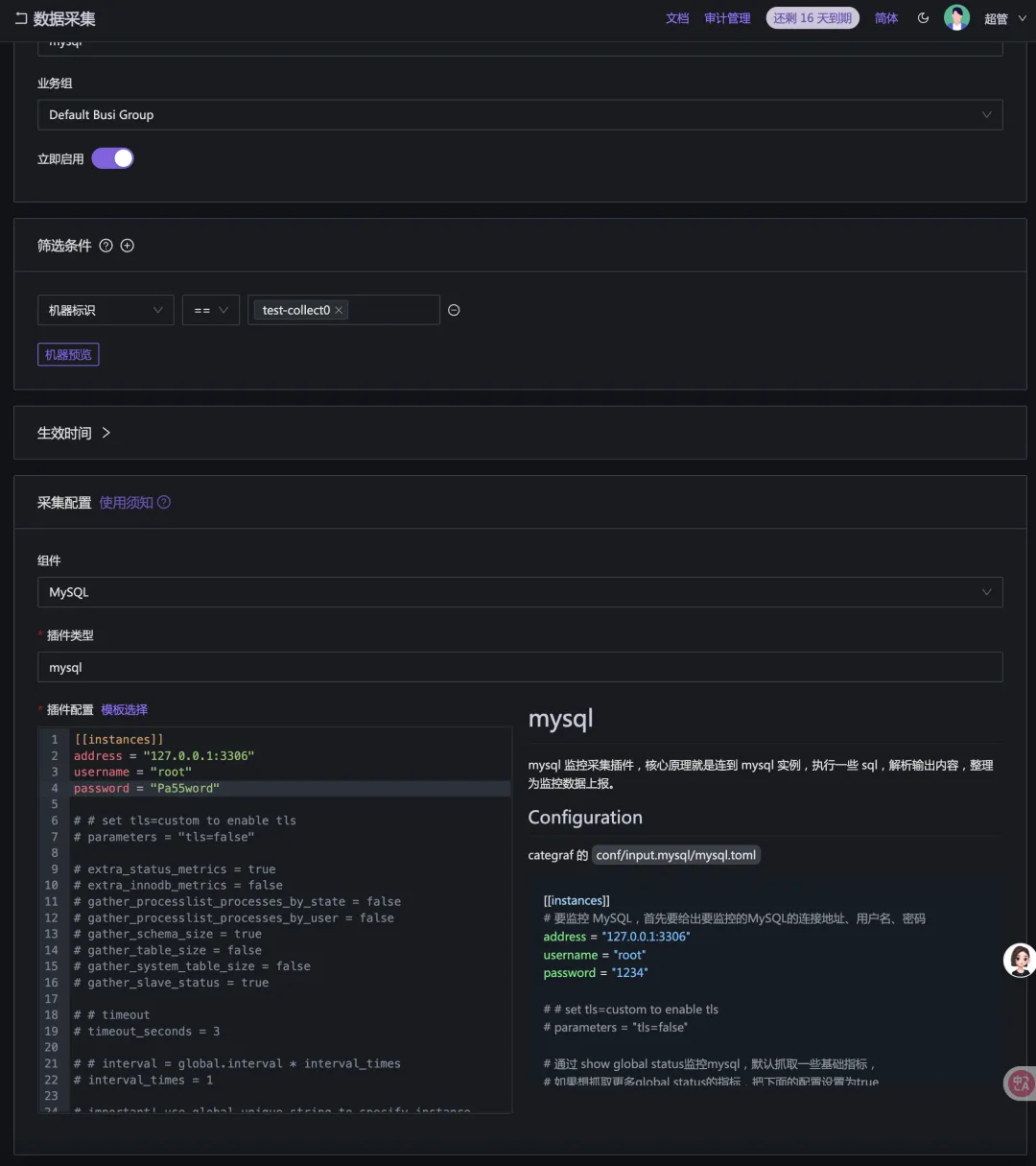
FAQ
1. 我的机器列表里可以看到机器,也可以看到机器的CPU、内存等信息,但是仪表盘查不到数据
💡 注意:机器列表里那些 CPU、内存等信息,不是存储在时序库的,而是存储在 Redis 中的,是 Categraf 调用夜莺的 heartbeat 接口时上报上来的,和 Remote write 走的是两个路径。
这个问题从如下几个方面排查:
1、看 Categraf 的日志
作为 IT 从业人员,第一反应就是应该看相关组件的日志,Categraf 的日志默认打在 stdout,如果是 systemd 托管的 Categraf,则使用 journalctl 查看,比如 journalctl -u categraf.service。如果对 Linux 不太熟悉,直接在命令行里前台启动 Categraf,可以更方便查看日志,即:
./categraf |
如上就是直接把 Categraf 进程启动在前台,日志会直接输出到终端,方便查看。
2、确认 Categraf 的配置
机器列表里可以正常看到内容,说明 Categraf 的配置里的 heartbeat 部分配置是正常的。仪表盘看不到监控数据,可能是 writer 部分的配置有问题,writer 部分的 url 应该配置为夜莺的地址,urlpath 是 /prometheus/v1/write。
3、确认夜莺的配置
Categraf 把数据推给夜莺,夜莺不直接存储数据,而是转发给 TSDB,TSDB 可以是 Prometheus 或者 VictoriaMetrics 等,夜莺把数据发给哪些 TSDB?是由夜莺的配置文件 config.toml 中的 Pushgw.Writers 来决定的。
需要确保 Pushgw.Writers 中的配置是正确的,且夜莺的 n9e 进程可以正常访问到这些 TSDB。
4、查夜莺的日志
如果数据转发给时序库失败,夜莺的日志会有相关提示,查看夜莺的日志可以帮助定位问题。社区里新手用户常见的错误是夜莺写数据给 Prometheus,但是 Prometheus 的启动参数有问题,没有开启 remote write 接口,导致夜莺写数据失败。这类错误通常会在夜莺的日志中有提示,可以直接看到应该给 Prometheus 增加什么参数,照着修改即可。
5、时间校准
比如本地笔记本电脑的时间和服务端的时间是否一致,监控系统对时间是很敏感的。如果时间没有校准,可能会导致数据无法正常展示。
6、查看仪表盘的配置
有些仪表盘是查看时序库里的所有数据,有些仪表盘是只能查看所属业务组下面的机器的监控数据(通过仪表盘变量控制的),如果是后者类型的仪表盘,就需要确保业务组下面有机器。
2. 我可否把监控数据写到 TDEngine 等其他时序库
首先,你需要了解 Prometheus remote write 协议(可以问问 Google 或 GPT)。Categraf 采集的数据是通过 Prometheus remote write 协议推送给夜莺的,夜莺也是通过 Prometheus remote write 协议把数据转发给时序库的。
所以,如果某个时序库支持接收 Prometheus remote write 协议的数据,那么就可以接入 Categraf 或夜莺。这个信息从哪里得到?去看(或搜)时序库的文档,如果它支持接收 Prometheus remote write 协议的数据,那么它大概率会在文档里提及。如果它的文档里没有写,大概率就是不支持或支持的不好不推荐使用。
3. 机器失联监控怎么做?
在 Prometheus 里,每台机器部署 Node-Exporter,Prometheus 主动去抓取 Node-Exporter 的数据,这种方式叫做PULL。这种方式的好处是,Prometheus 可以知道机器是否失联,因为如果机器失联,Prometheus 就无法抓取到数据。抓取成功的话,会有个 up 指标,值为 1;如果抓取失败,则 up 指标的值为 0。
所以,在 Prometheus PULL 模式下,可以使用 up 指标来监控机器是否失联。
夜莺默认使用 Categraf 采集机器的监控数据,Categraf 不暴露 /metrics 接口,而是通过 remote write 协议把数据推给夜莺,这种模式称为PUSH。在这种模式下,不会有 up 指标,那如何监控机器是否失联呢?
夜莺的告警规则里,提供了一个 Host 类型的告警规则,可以配置失联告警:
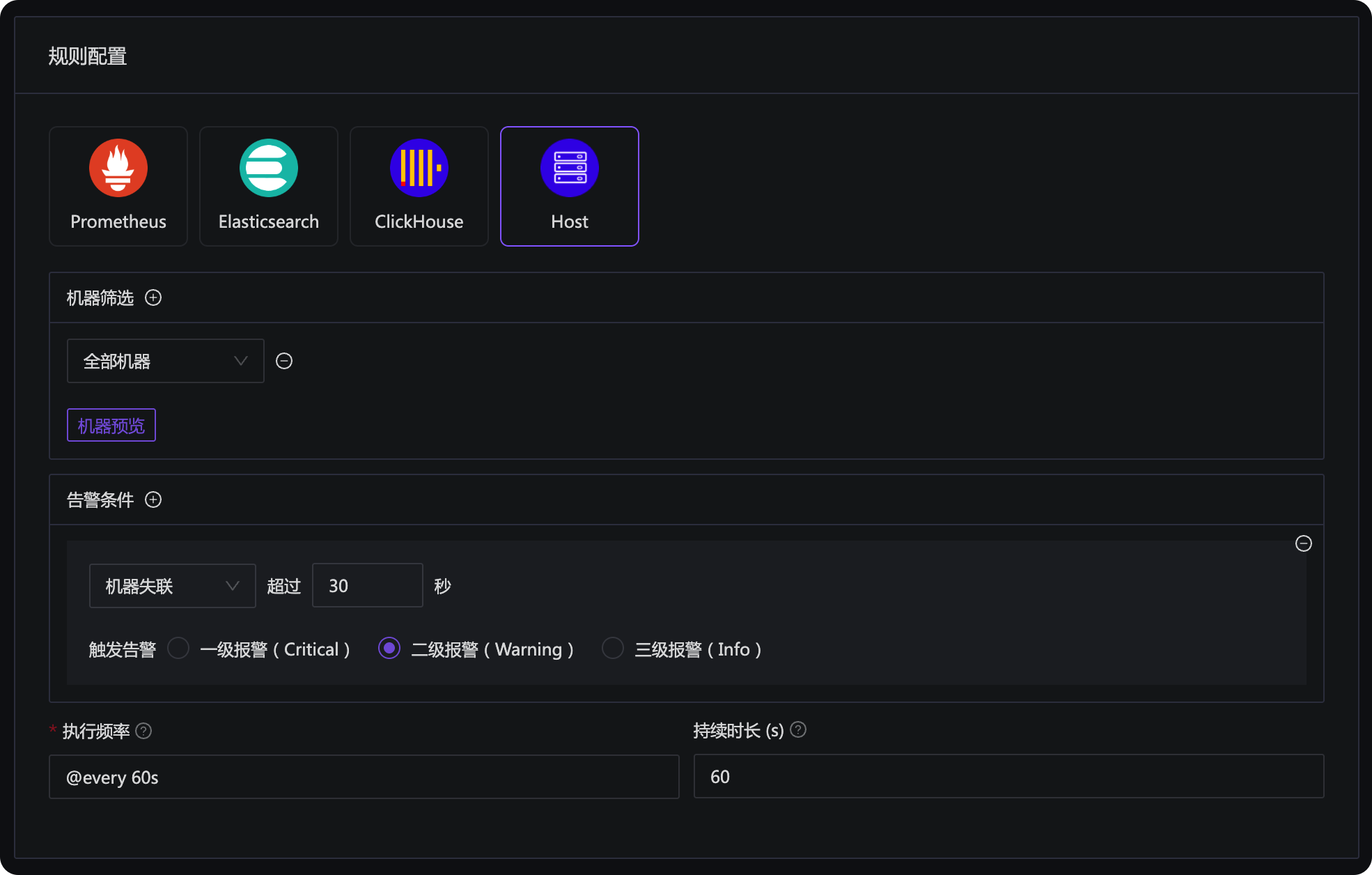
通常配置为对所有机器生效即可,如果你有一些特殊的机器,不想做失联告警,可以把这些机器放到特殊的业务组或者打上特殊的标签,然后在机器筛选这里,给过滤掉。
或者使用 PING 监控对机器发起 PING 探测,然后对 PING 的探测结果配置告警规则,也是可以的。有很多监控工具都支持 PING 探测,比如 Telegraf、Categraf、Blackbox Exporter 等。